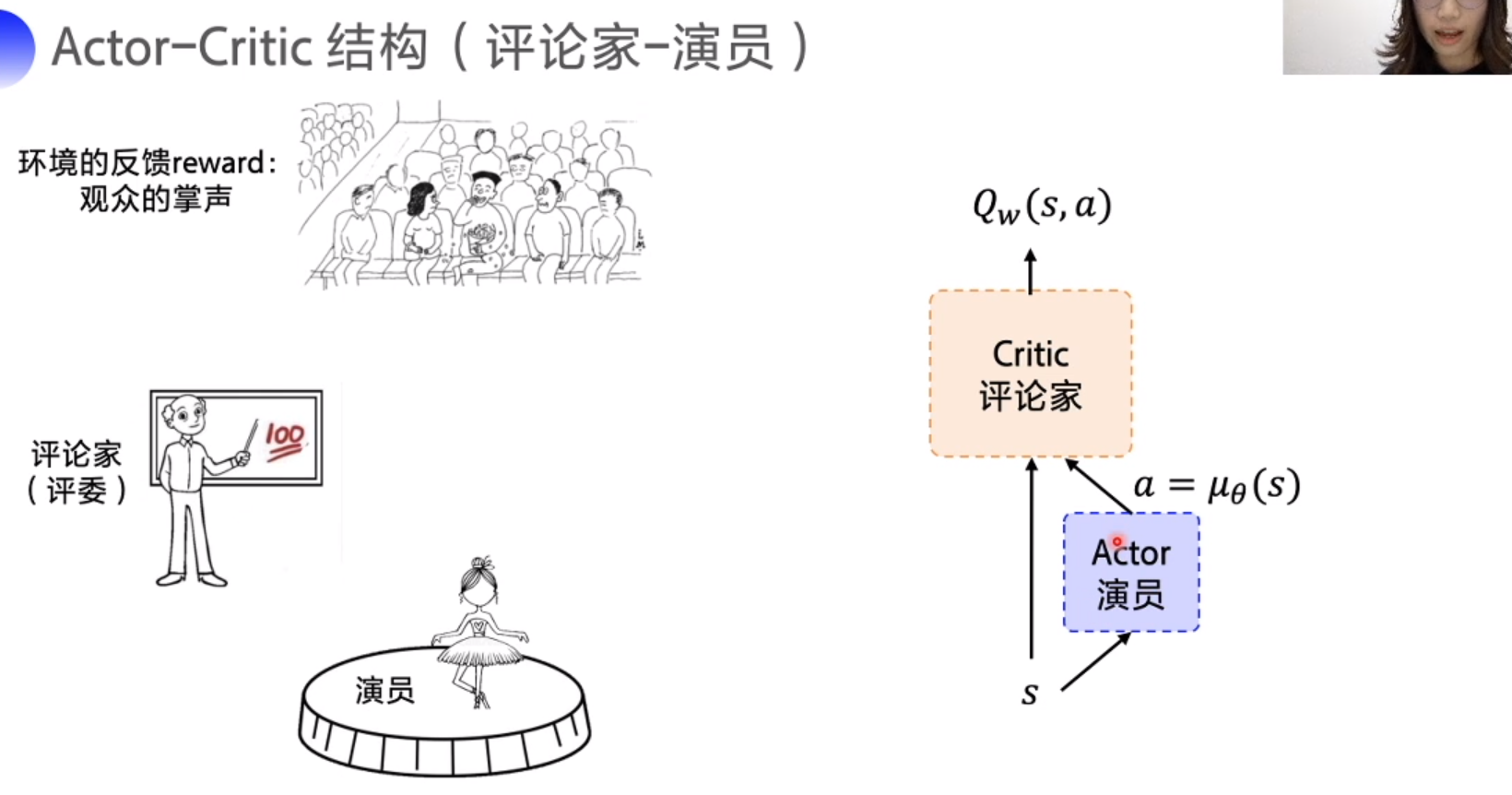
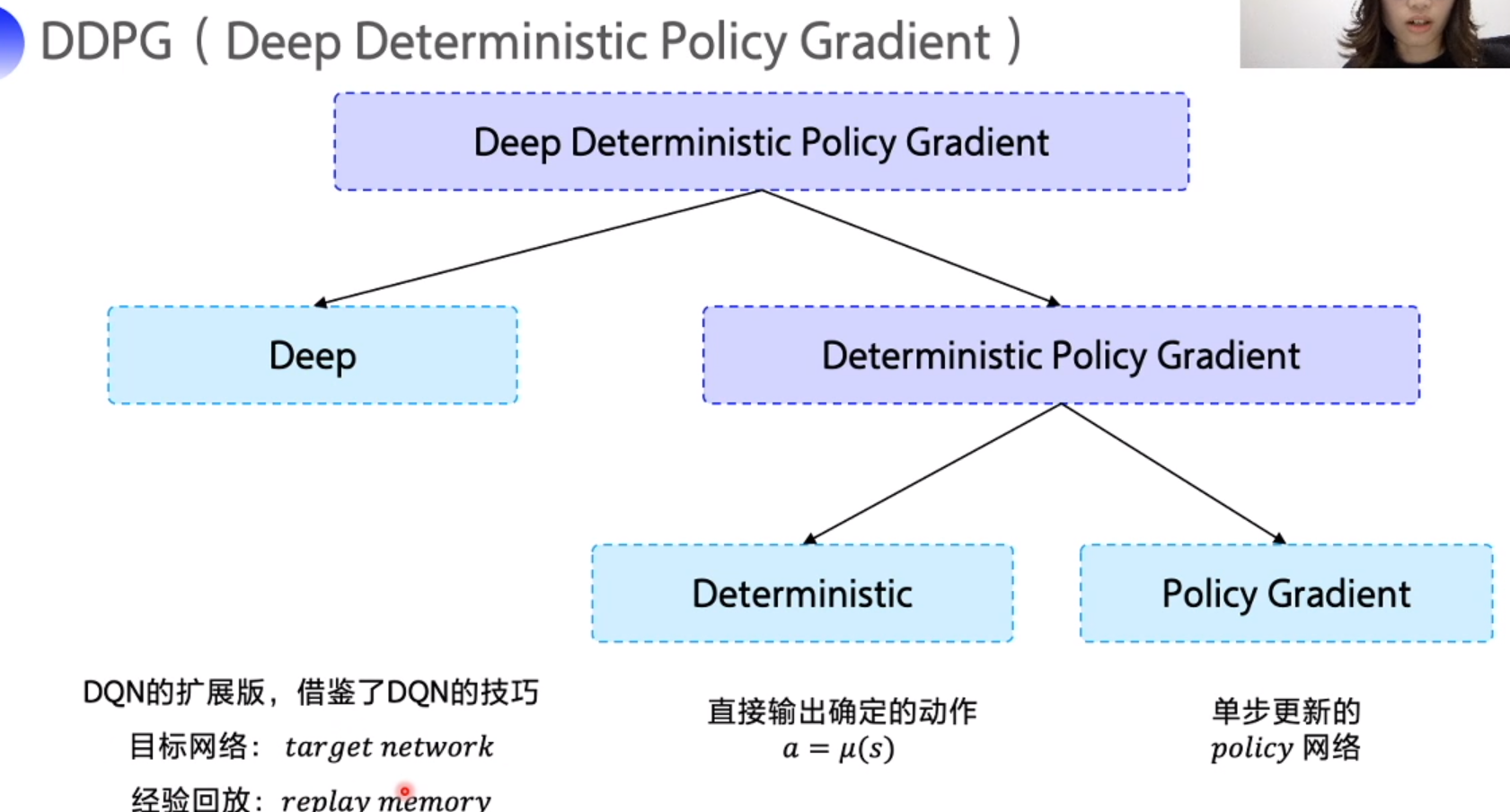
DQN 扩展到连续控制动作空间
策略网络负责对外展示动作, critc 对action 打分,action -> Q value,迎合评委网络使 Q 尽可能高

Q 网络逼近 Q-target, 使用 MSE
Q target 不稳定,所以专门建立 target_Q 和 target_P 网络(next_action )

为了防止 target_Q 网络更新, (定期copy), 需要 stop gradient
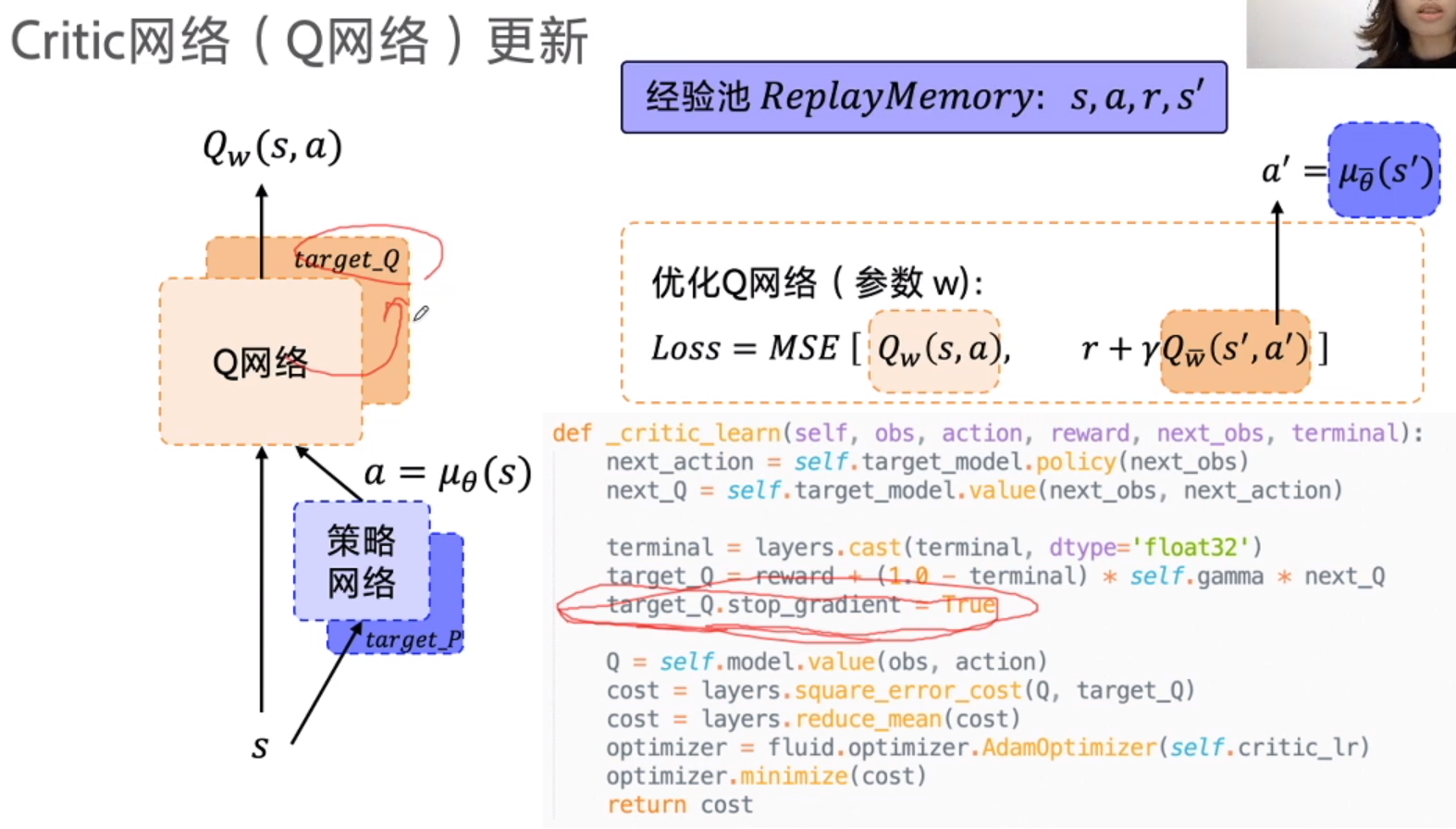

只更新 , 所以minimize 中 传入要更新的 actor 参数

总结
