用户系统

Scenario(QPS)&Service
QPS = DAU*用户平均每天请求次数/每天多少秒(86400)

QPS与数据存储

Cache(读多写少)
File system 可以作为网络请求和计算结果的cache
跟hashmap区别,cache有淘汰机制(LRU,LSU)

ttl: time to live

Set User
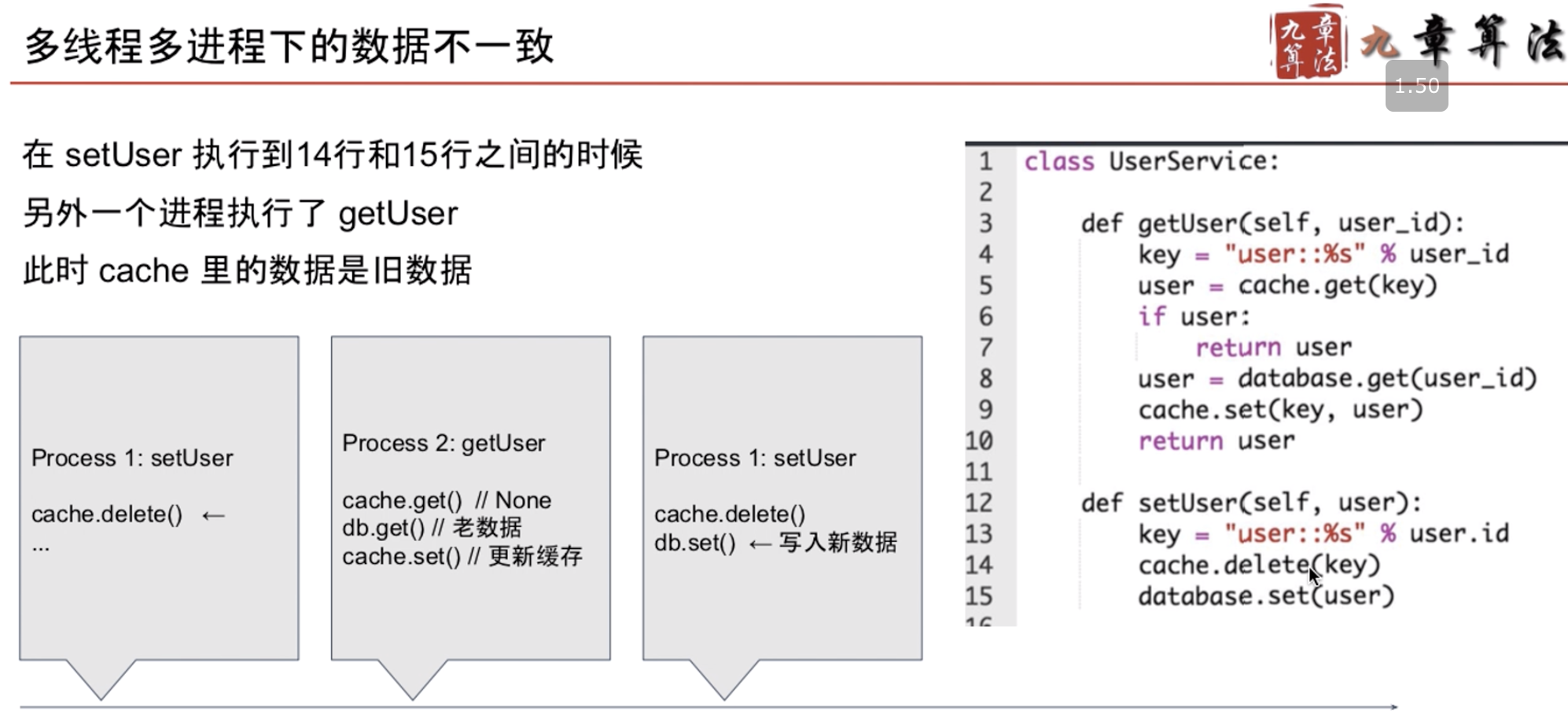
cache delete, database set.有可能第二个

多线程下,可能造成数据不一致。
当执行完cache delete, 另外线程get user 获取了旧数据(cache), 再执行database set (新数据->数据不一致
加锁(不同机器,系统)
常用方法
database.set, cache.delete

同时用 set set, 多进程会有修改数据库情况,然后缓存set旧的data
第一种情况因为读多改少,出现概率低。cache hit 概率大,通常>98%
如何解决一致性 问题
ttl(time to live) 允许短时间的不一致
读少写多 (多用数据库,分摊请求)
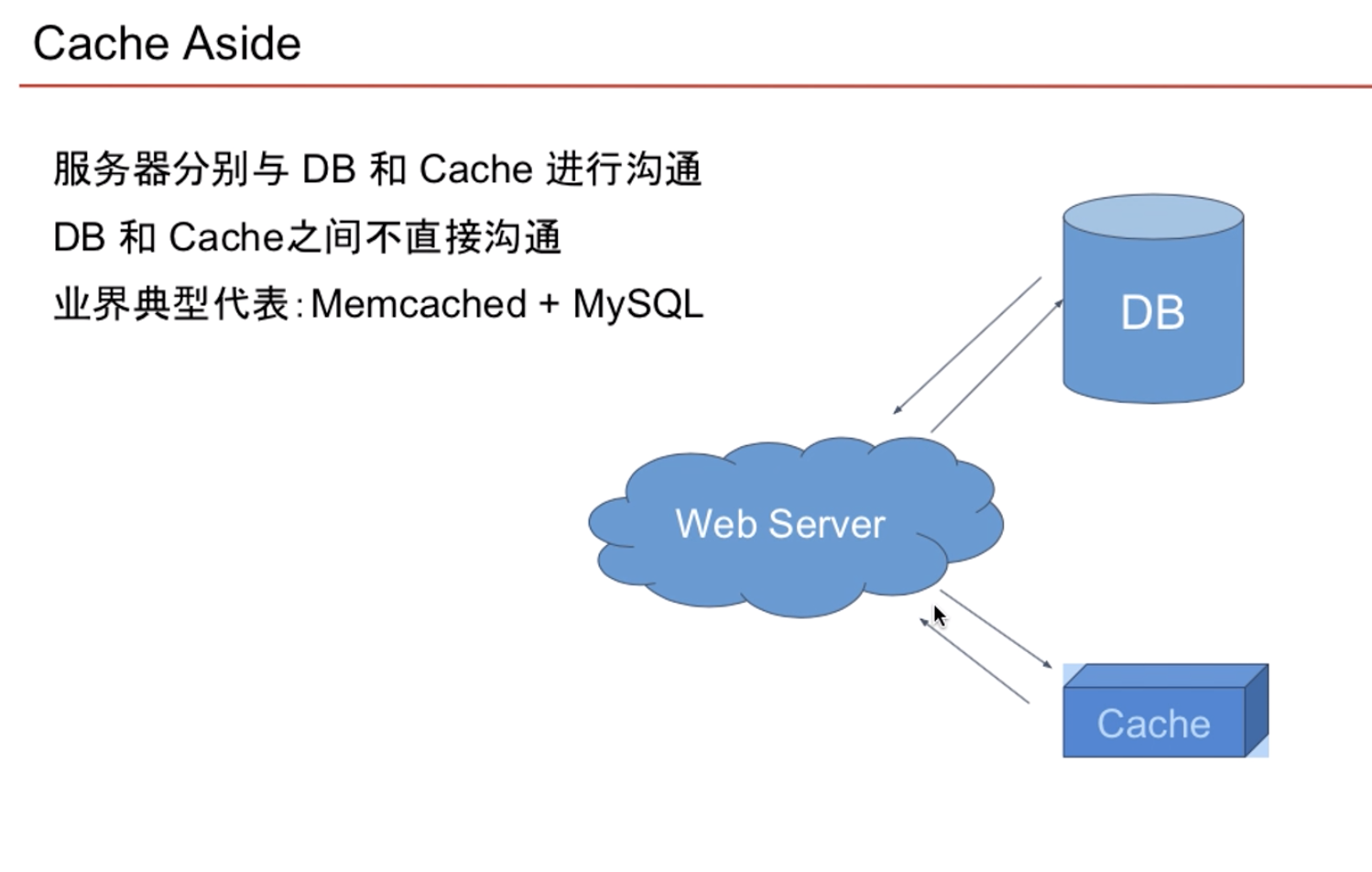
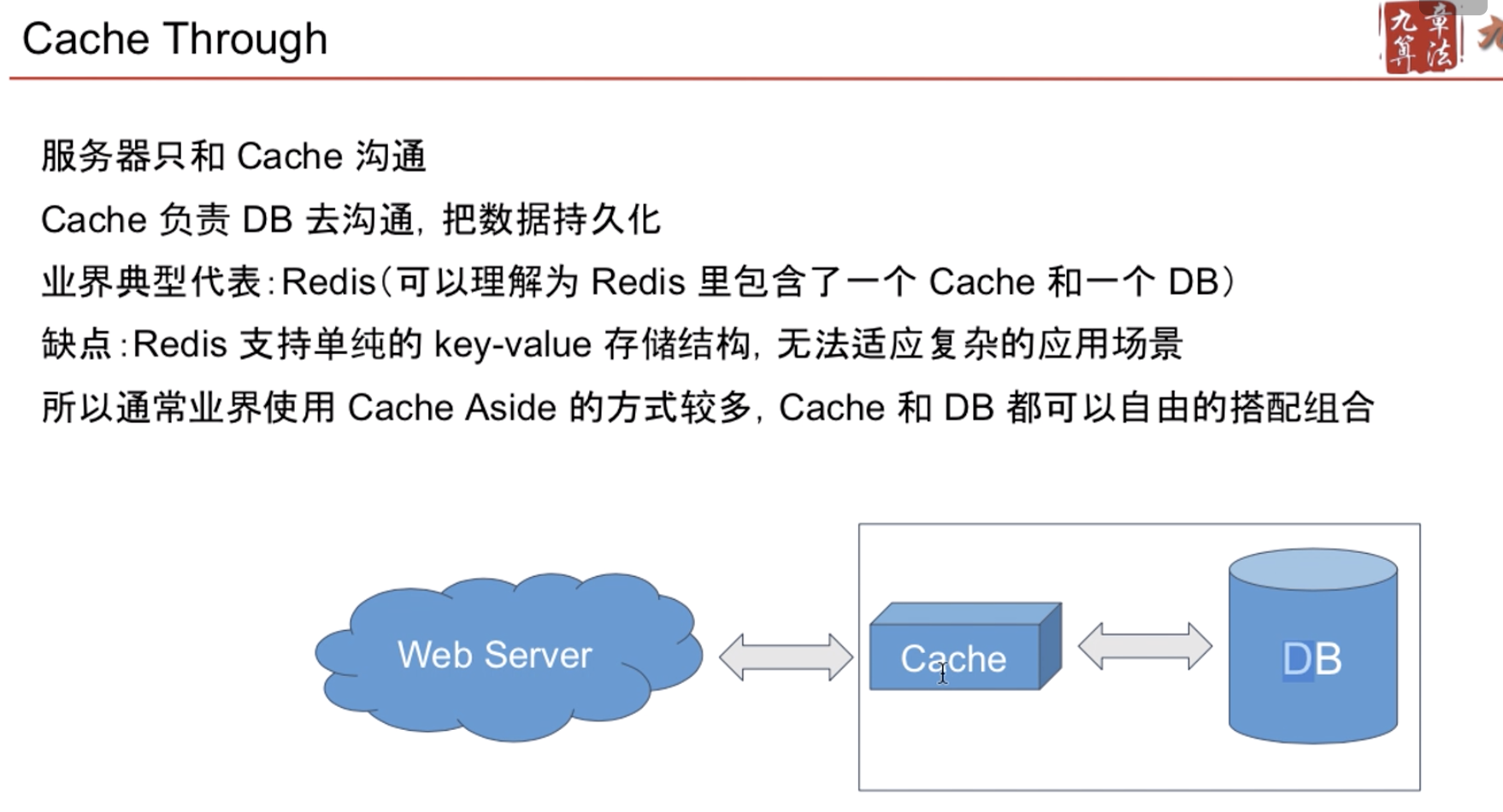
Cache 架构
登录系统

UUID:通常用UUID来作为Session Key(Session Token),UUID(Universal Unique ID): UUID是由一组32位数的16进制数字所构成,所以UUID理论上的总数为1632=2128,约等于3.4 x 10^38。也就是说若每纳秒产生1兆个UUID,要花100亿年才会将所有UUID用完。所以通俗的称之为宇宙爆炸都不会出现重复的ID字段。
Cookie里内容越少越好

只允许一台机器登录
存储device token, 监测到不同device, 把其他设备账户logout
好友关系

方案1:
优点:只存储1条数据,节省一半空间。(当你要存 1 和 2 是好友的时候,你可能存为 <1,2> 也可能存为 <2,1>。我们只存成 <1,2> 的形式,原因有两个,第一是方便查询,否则你查询的时候得分别差 <1,2> 是否存在和 <2,1> 是否存在。第二个是节省一半的存储空间。)
缺点: 查询时 or 操作慢一些
方案2:
优点: 查询语句简单,查询速度快。空间换取时间
Transaction: 事务。代表一些列操作要打包在一起,同时成果或者同时失败。比如我转你 10 块钱,你的余额要 +10,我的余额要 -10。这是两条数据库操作,必须同时成功或者同时失败。不能只有一条操作成功。这种打包,就叫做 Transaction。
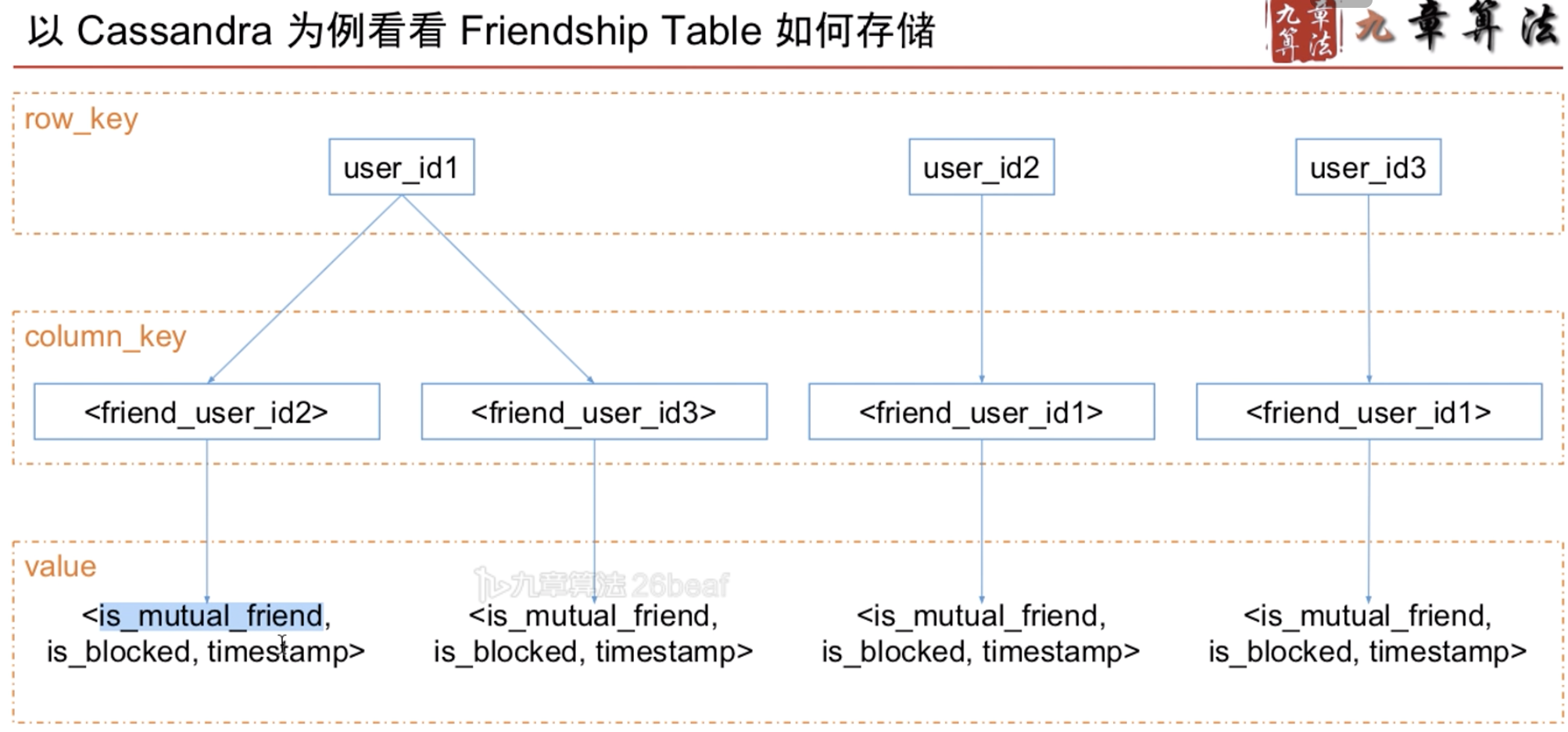
NoSQL(Cassandra)

Row key: 存储到哪台机器的索引,nosql 用于分布式


Column key: 支持范围查询 和 复合值查询
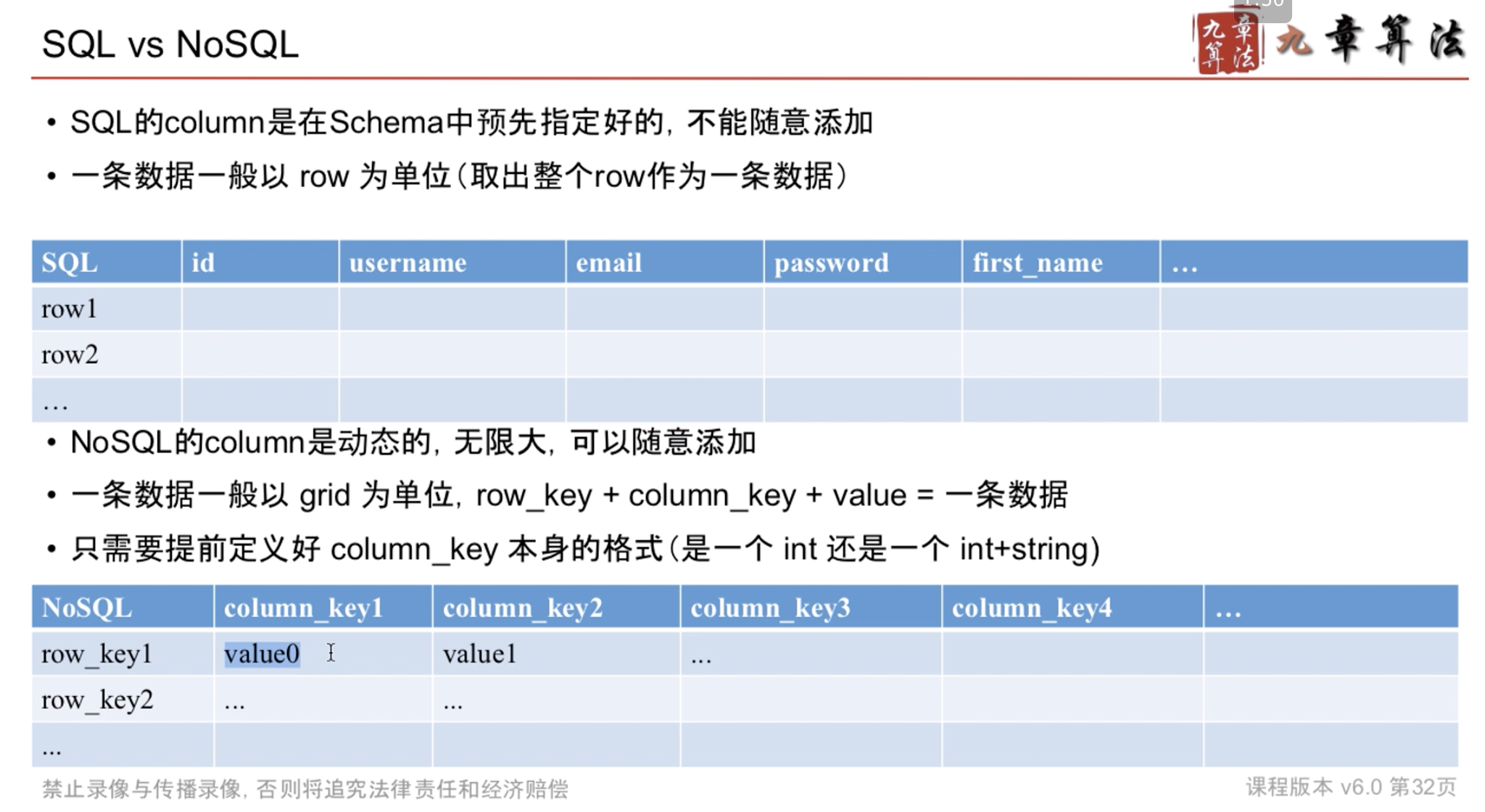
NoSQL VS SQL
选择原则:
- transaction 不能选NoSQL(通常在一台机器完成)
- 擅长部分
- 一个网站会使用多种数据库

NoSql 存单向好友关系

NoSql 存储User
根据 emial/phone/username查询

共同好友
A userid B userid => A和B交集

六度关系
