Scale
QPS
Single point failure(一台服务器挂)
sharding 数据拆分
- 解决 single point failure
- 分摊流量
replica 数据复制
- 数据恢复
- 分摊流量
数据库拆分
竖向拆分


缺点: 当表单特别大,column无法拆分时无法用
横向拆分
新数据放新机器,老数据放老机器的问题是什么?
根据数据的新旧程度来拆分的话,新数据的访问次数比旧数据的访问次数是要明显多的,会导致数据访问不均匀的问题。
这种方法并不会导致存储不均匀,最多只有最新的一台机器的数据相对少一些,其他的机器都还是均匀的。也不会导致不知道数据去哪台机器取,比如根据 id 来拆分,0~99在1号机器,1-199 在2号机器的话,根据 id 可以算出对应的机器是哪个


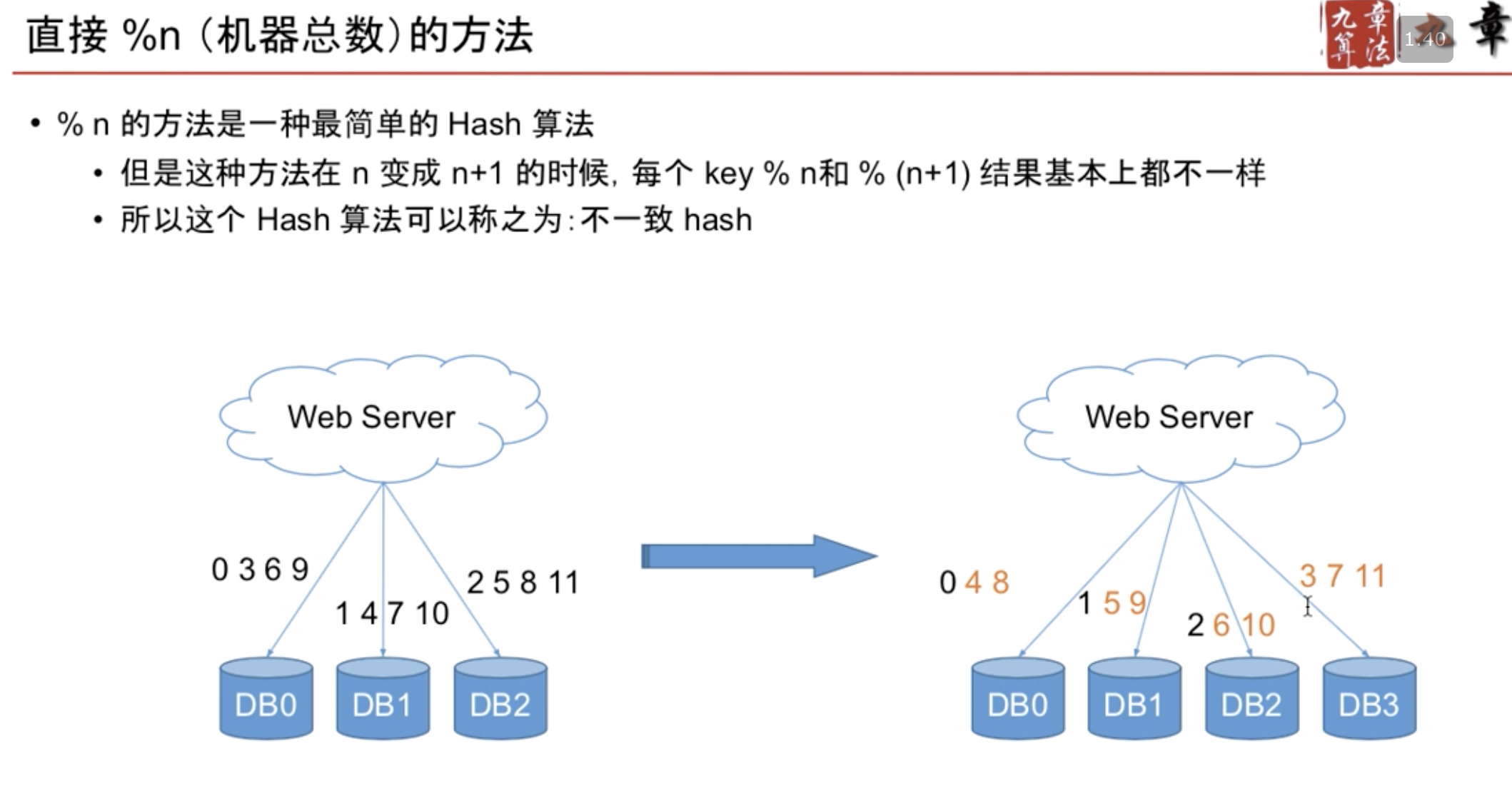
75%的数据迁移
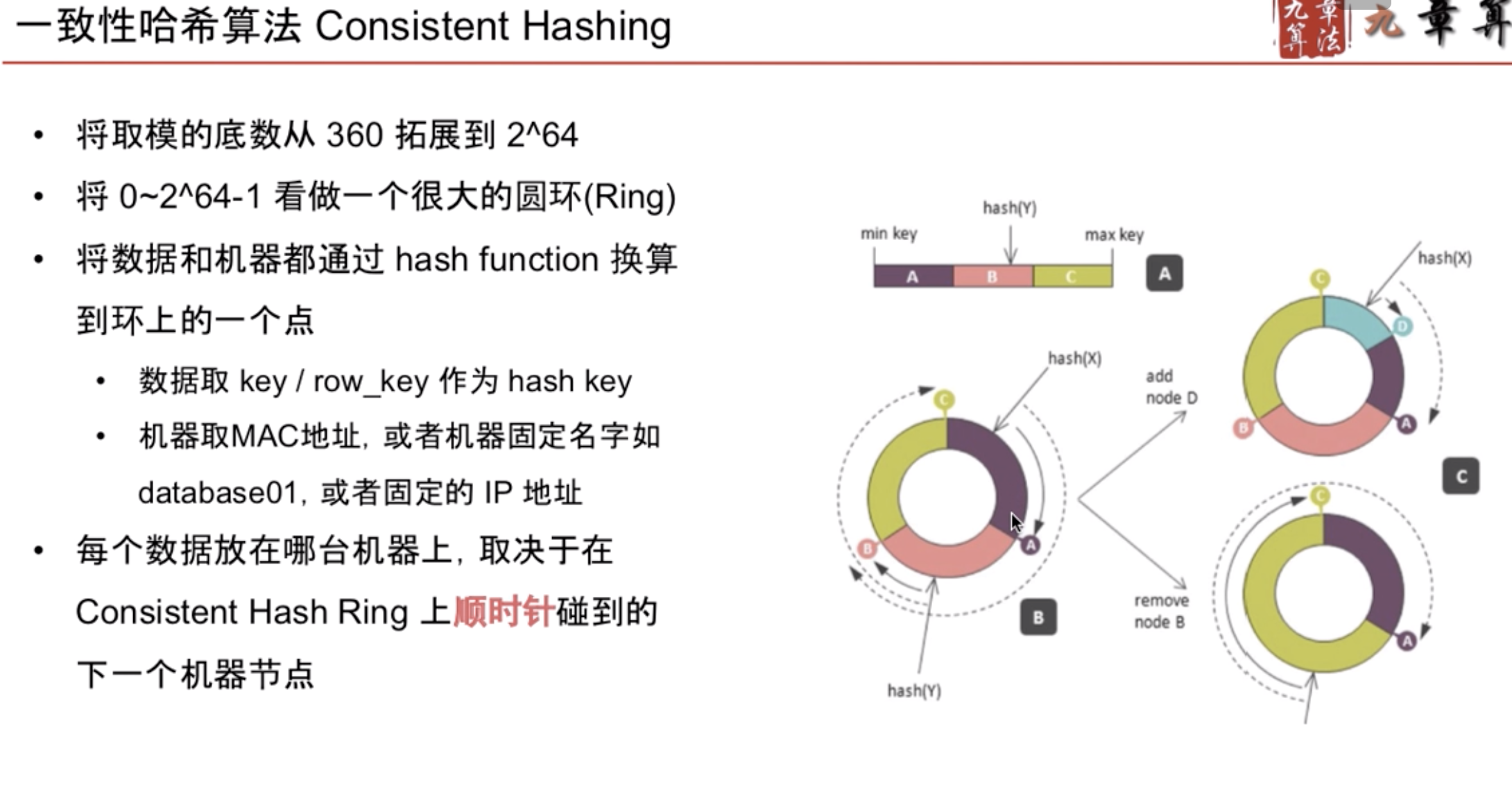
一致性哈希算法
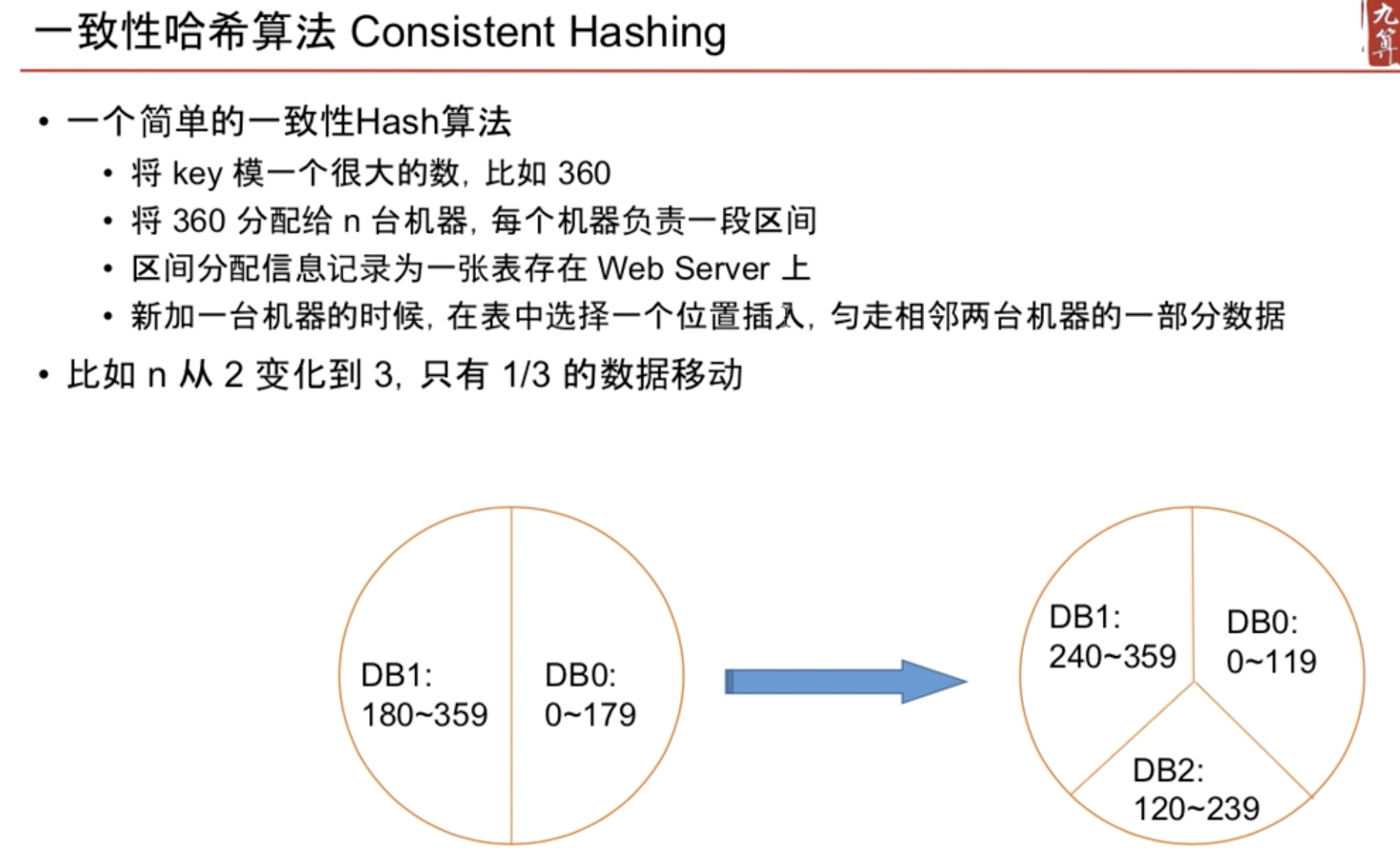
匀走相邻两台机器的一部分数据
缺陷:


改进:
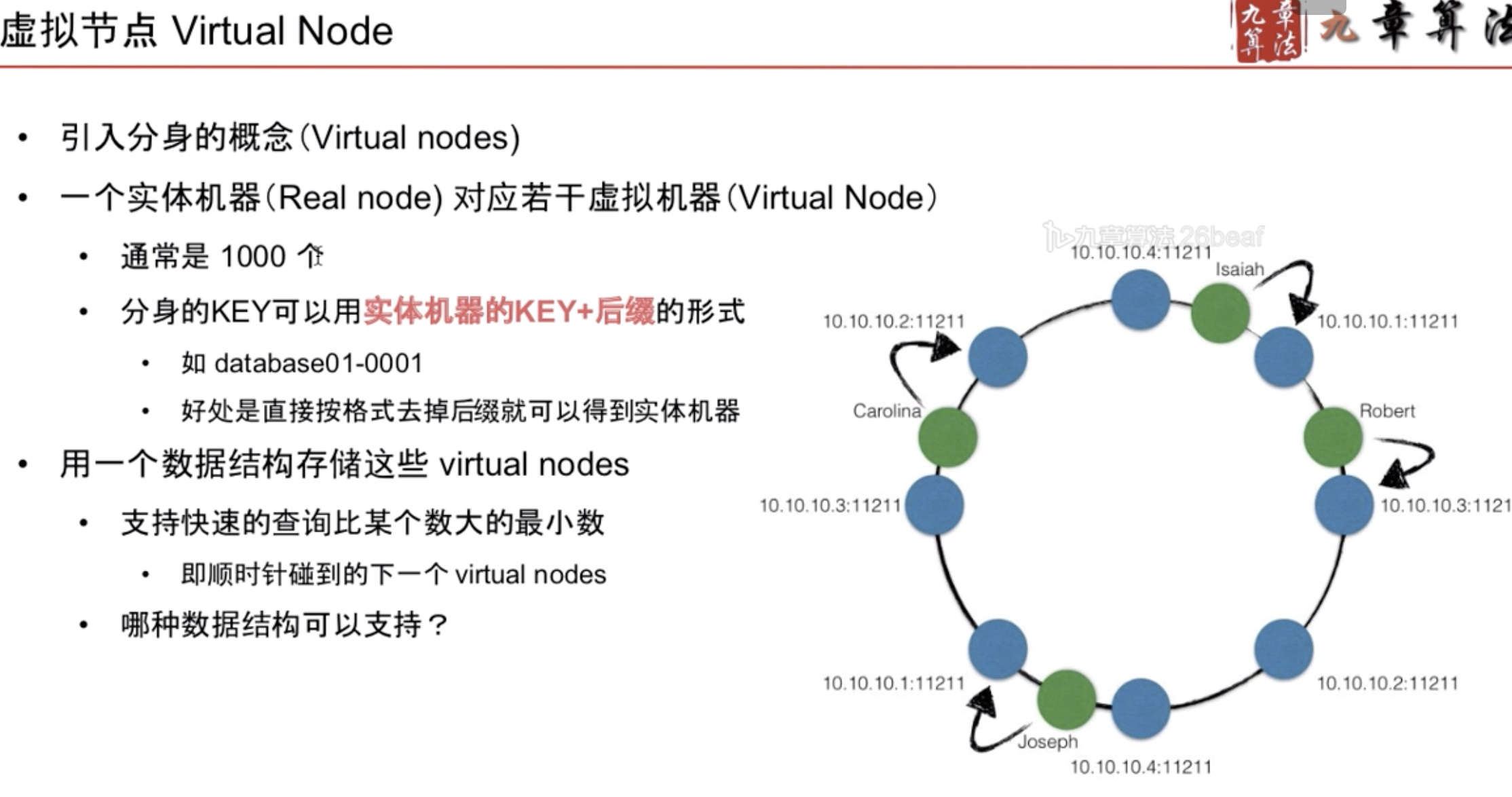
红黑树(balanced tree)
数据复制 Replica
Replica vs Backup

SQL

NoSQL

实战1:User Table Sharding
怎么取数据就怎么拆数据库
按照 username找用户 查username->id表

实战2:Friendship Table Sharding
双向好友关系,必须存两条关系
实战4: News Feed/Timeline Sharding
owner id/userid
实战5: LintCode Submission (user/problem/status)
