什么是强化学习?

两部分 三要素
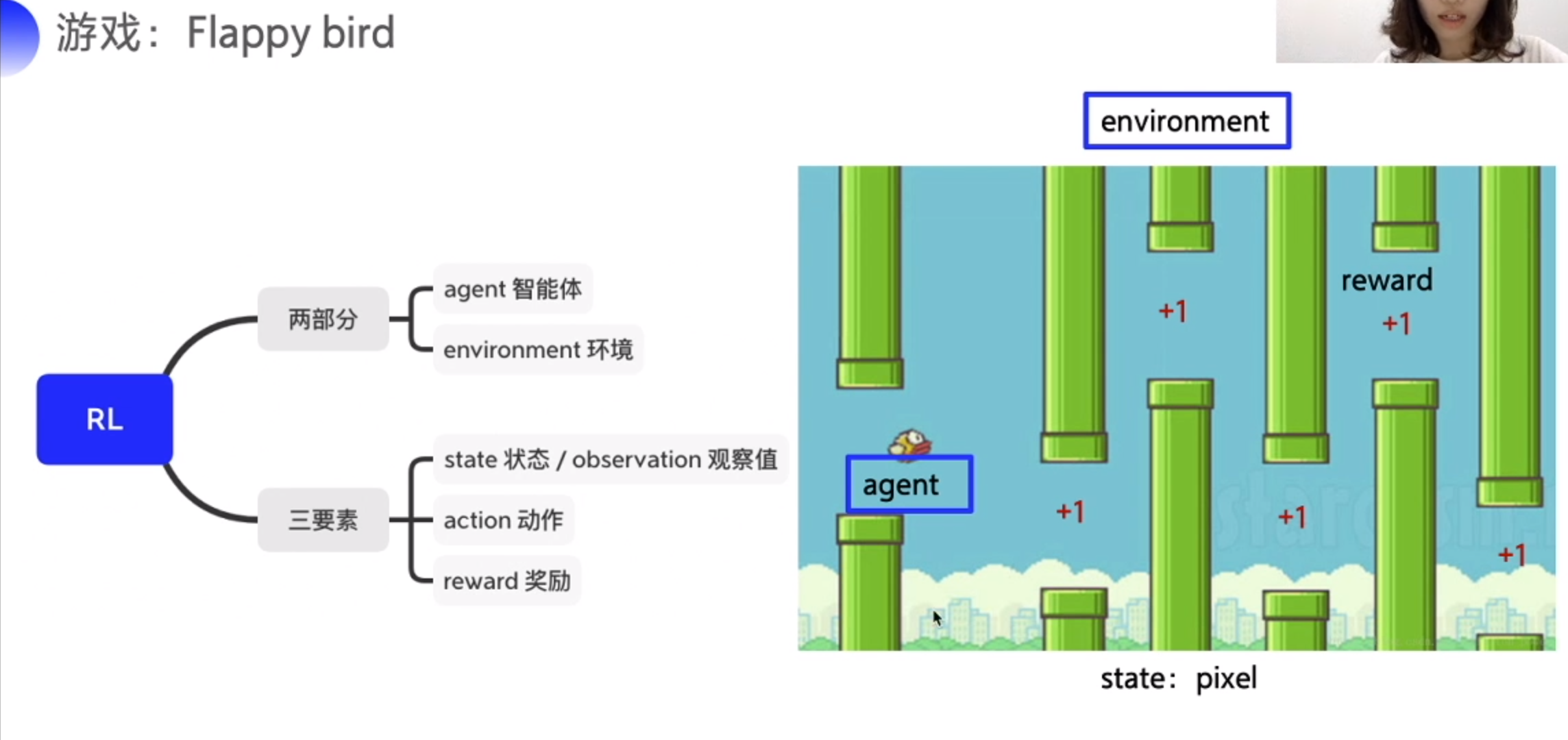
在 Flappy bird 中
| agent | environment | state | action | reward |
|---|---|---|---|---|
| 鸟 | 鸟周围的环境,水管、天空(包括小鸟本身) | 拍个照(目前的像素) | 向上向下动作 | 距离(越远奖励越高) |
动一下截个图 再决定下一个动作
跟环境交互,决策。
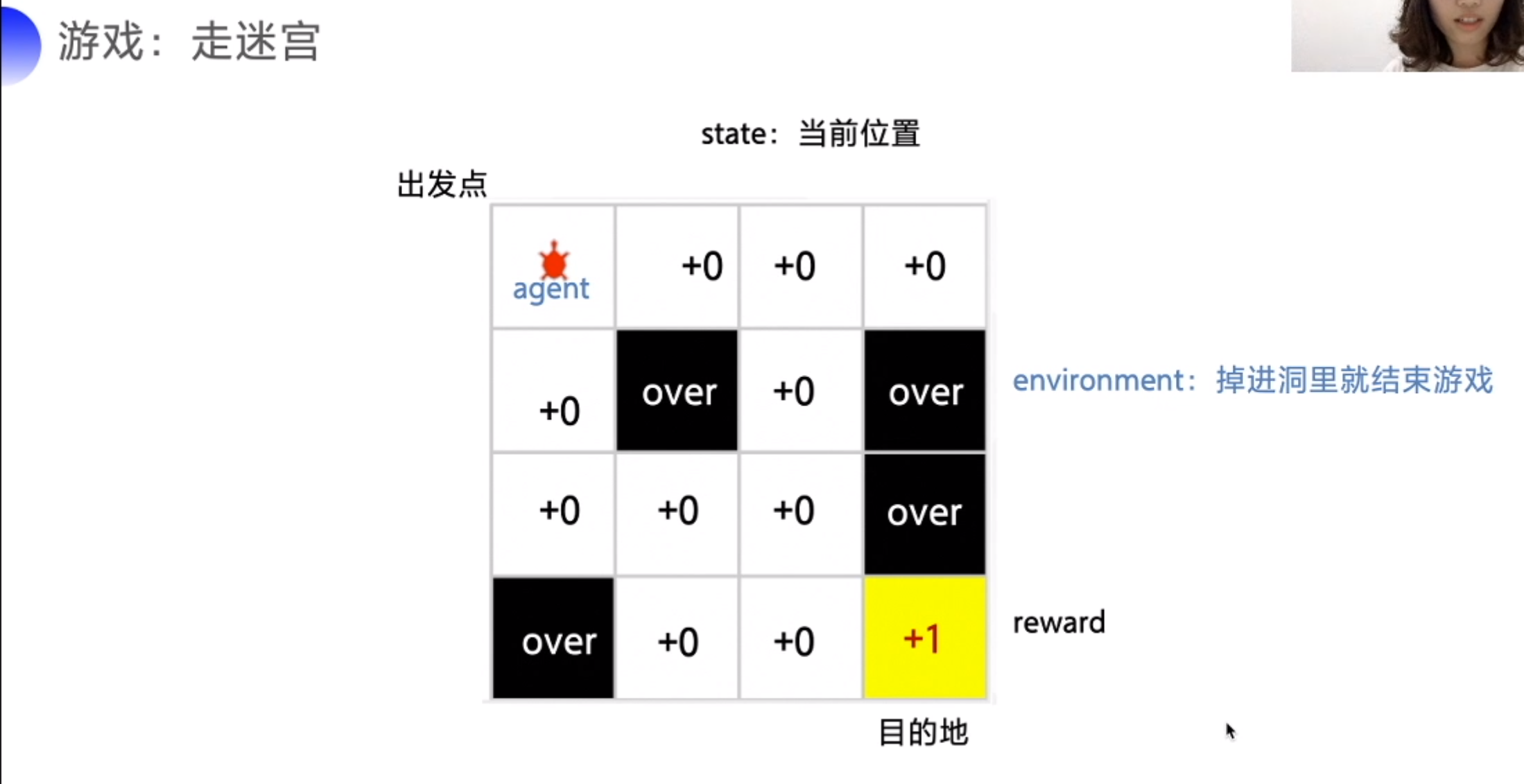
奖励是延迟的。迷宫走完,才有奖励。

强化学习和其他机器学习的关系

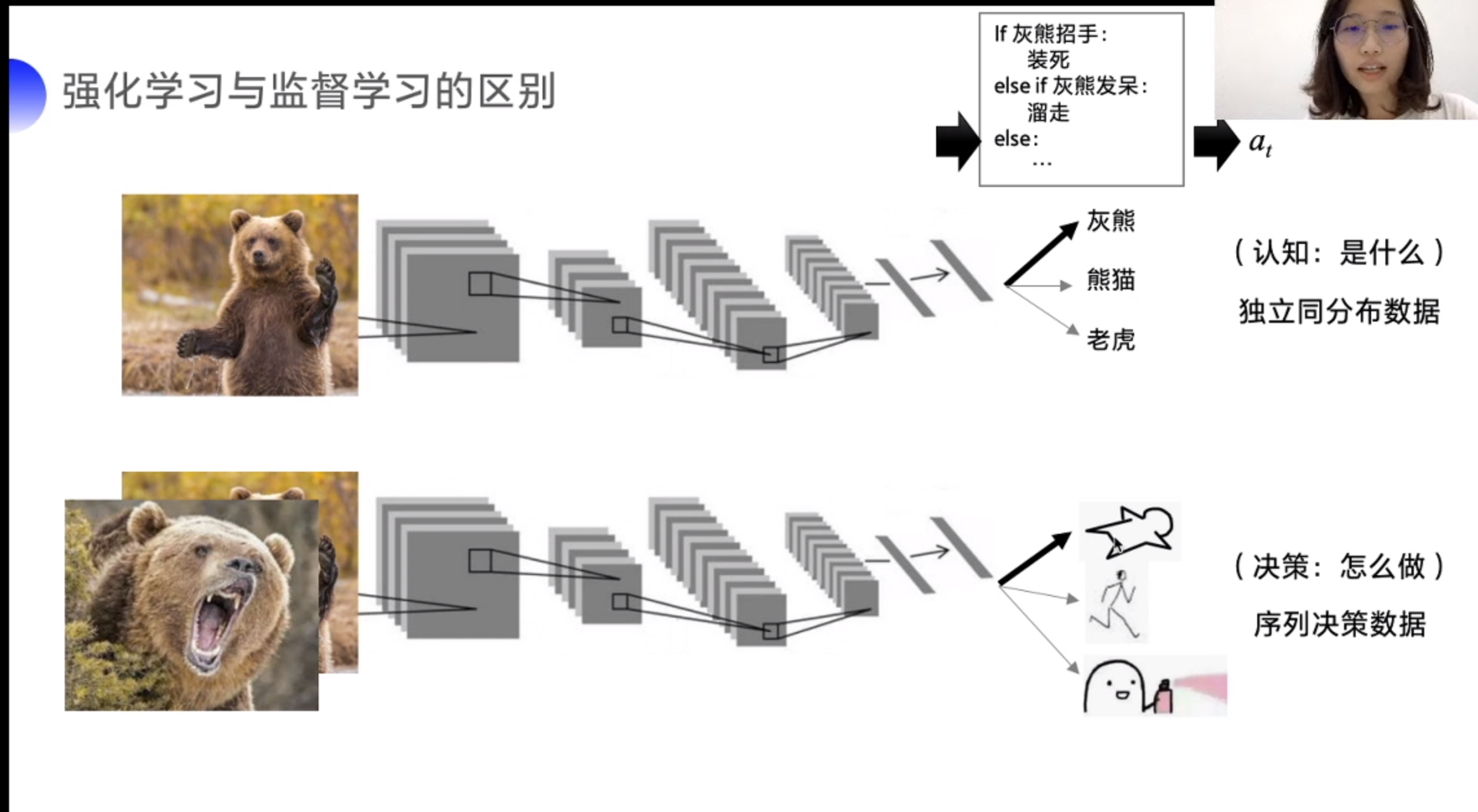
监督样本一般样本内无关系。强化学习,样本之间相互影响。

基于价值会向固定方向走,基于策略随机性更高一些。
RL agent <-> environment 交互接口

reset 重置
render 渲染目前
step 交互一步
Step 输出参数

- 1-36 位置(36格内的位置)
- -1 reward(奖励,每走一步会有惩罚,目标最少步数走完)
- true/false 游戏是否完成
- info 额外信息
git clone --depth=1
depth 用于指定克隆深度,为 1 即表示只克隆最近一次 commit. 可以解决项目过大的问题
总结
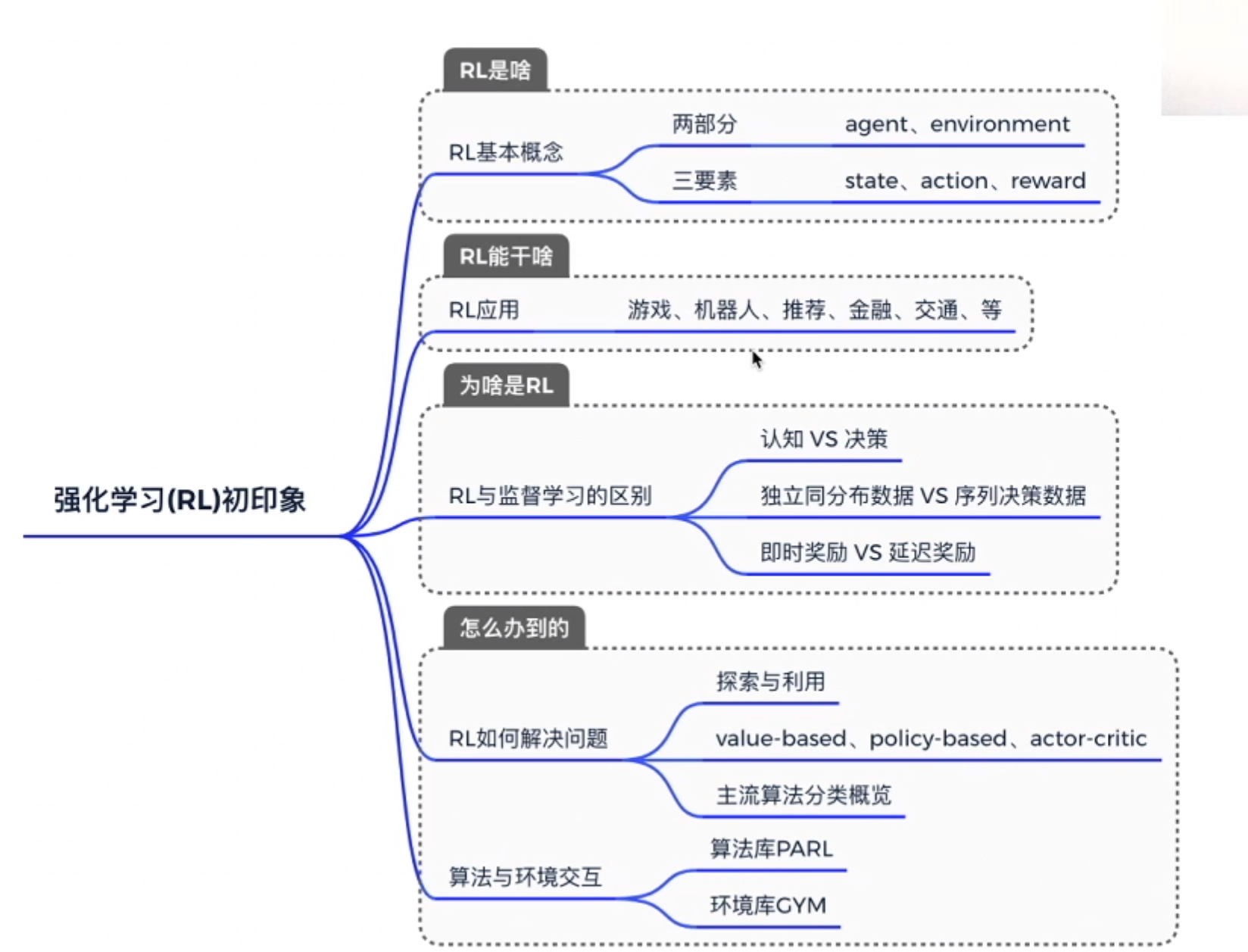
图片来源:PARL 强化学习公开课 Lesson1