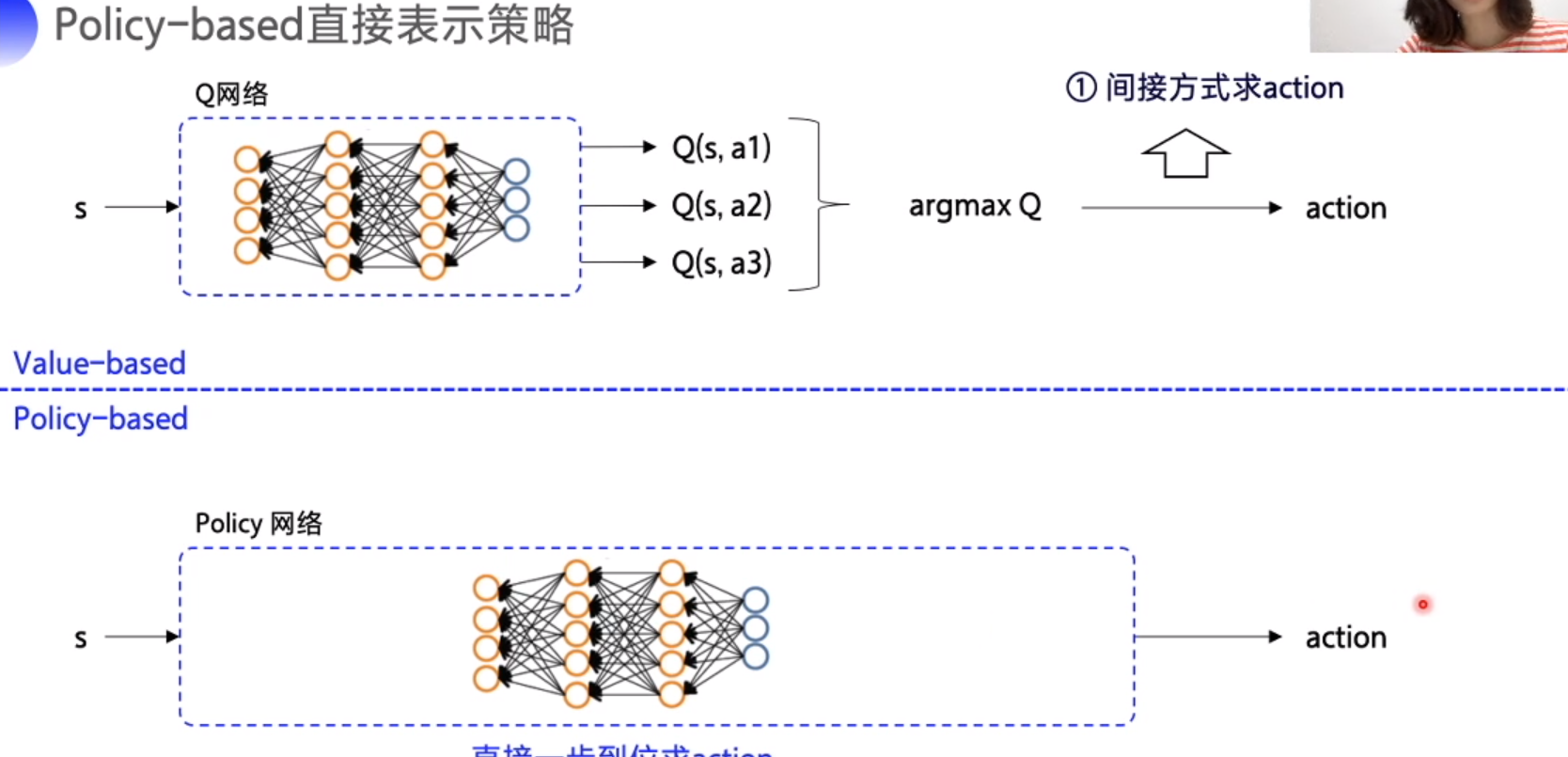
Value-based vs policy-based

policy based : 直接求action
policy based: 输出动作的概率

最后一层 softmax
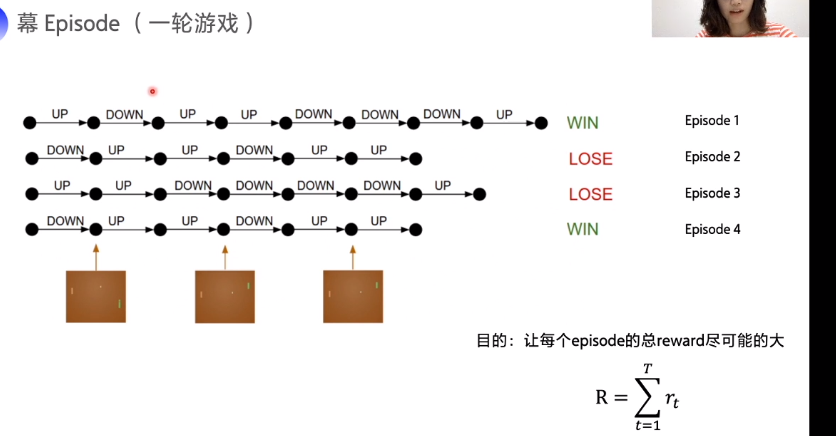
episode: 每轮游戏
优化目的: max 每个episode的总reward
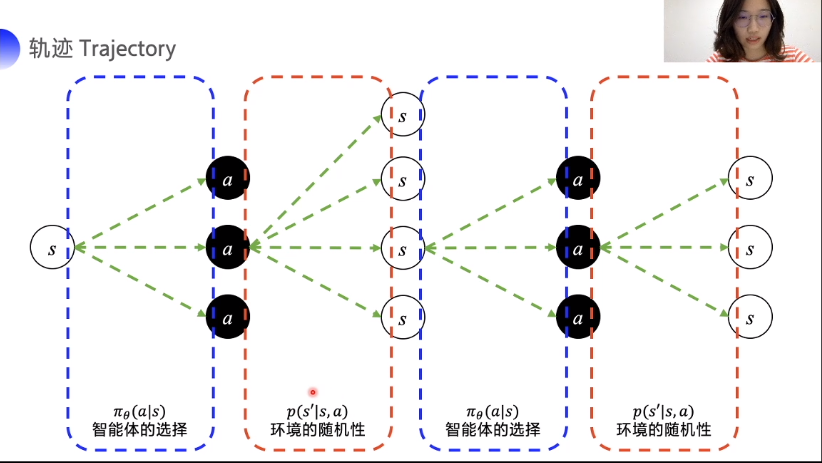
环境的随机性无法控制
期望回报

环境概率是未知的, N是 episode数。
优化策略函数
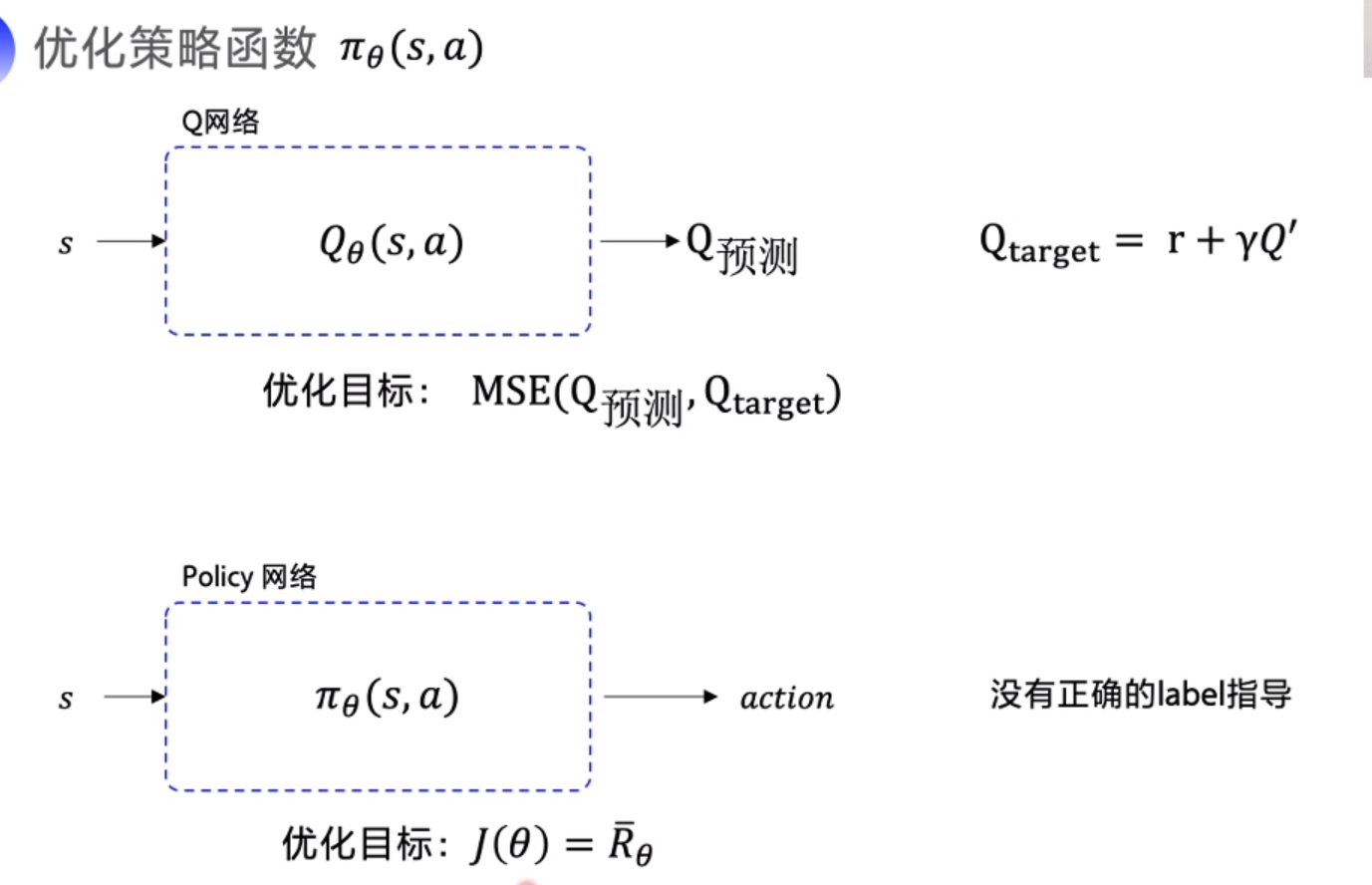
优化目标 期望回报最大, 梯度上升
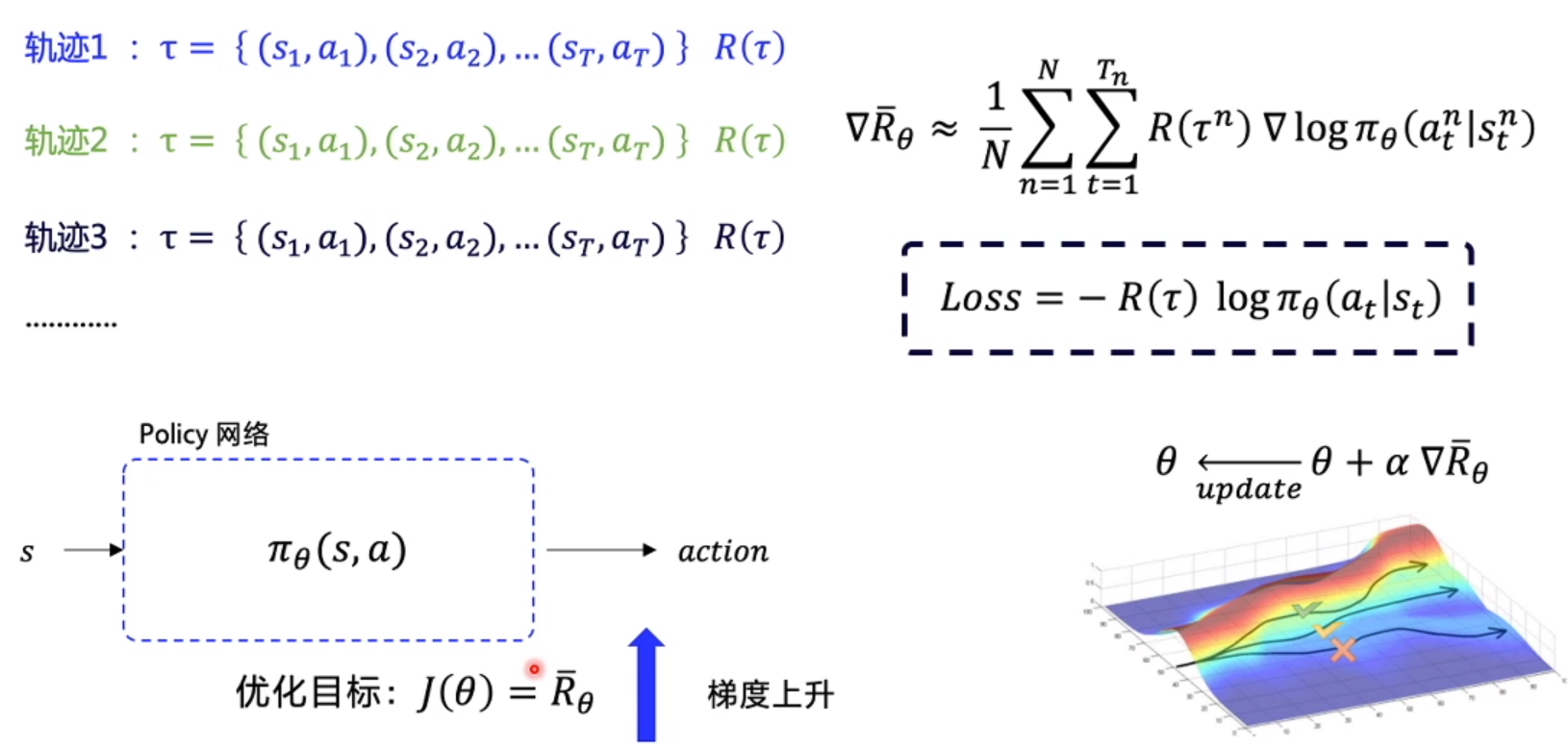

蒙特卡洛每个 Episode 更新一次, 时序差分每个action更新一次

根据公式反向推到
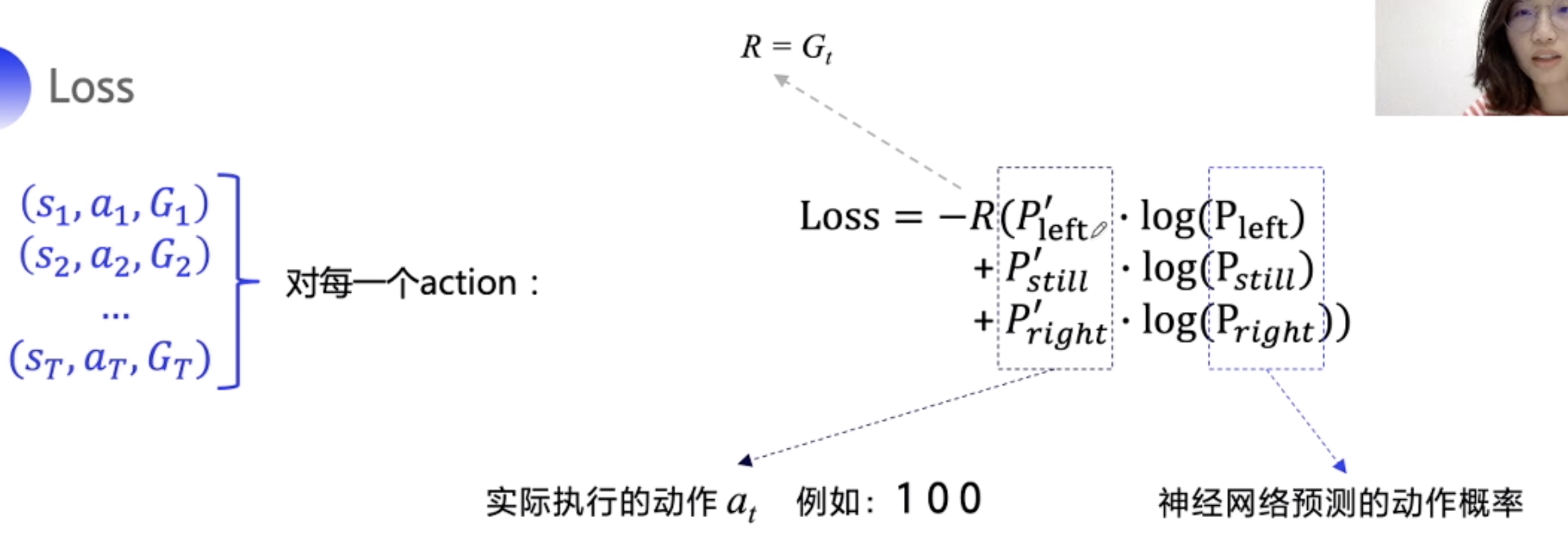
Reinforce
每个 Episode , 通过 求出 G_t, 对于每一步使用 ln 函数更新神经网络参数值

类比 Cross entrophy, 因为sum_ln 不一定是正确的acition, 只是真实的action, 所以需要乘上总奖励系数 G
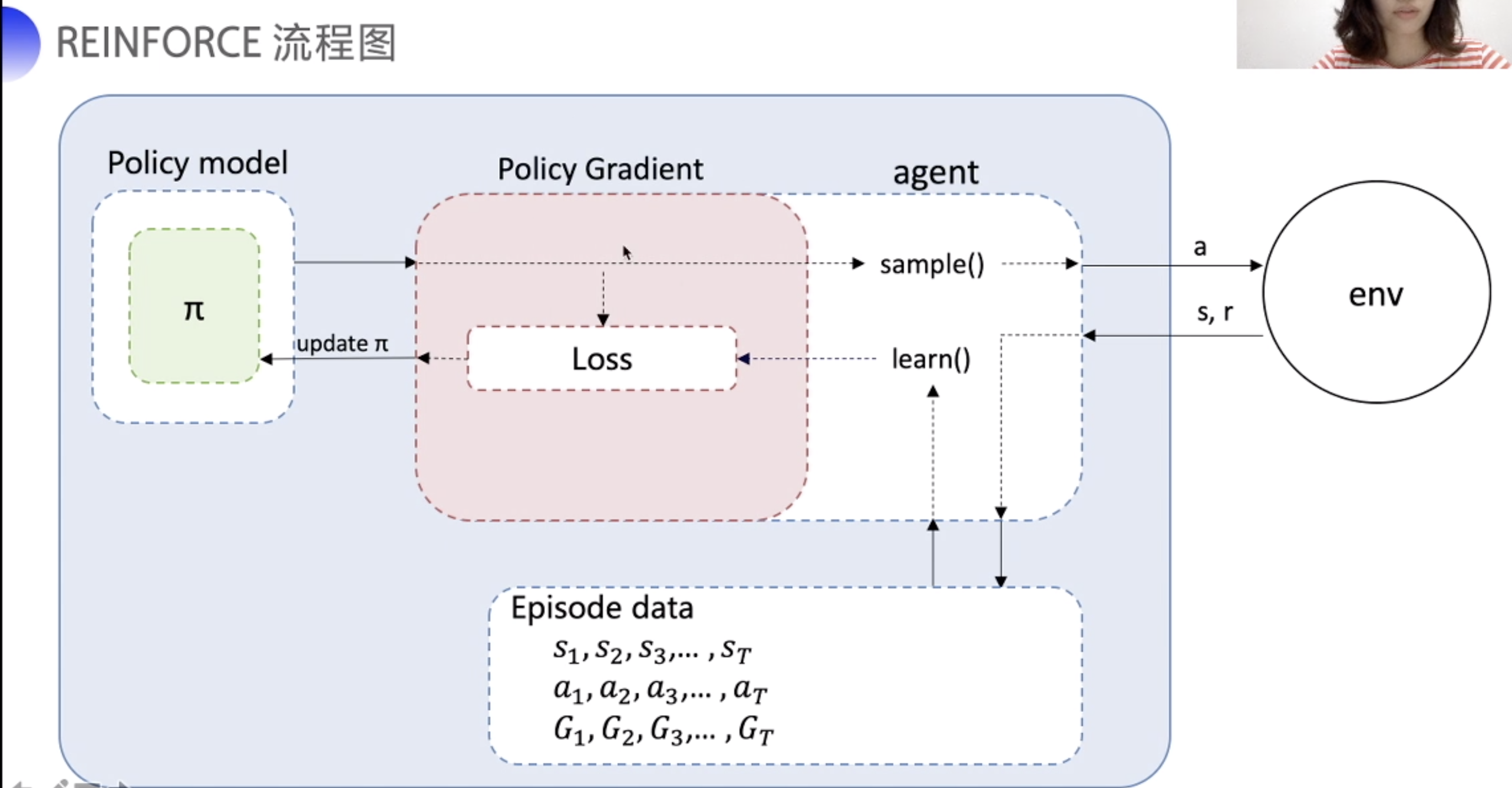
流程图
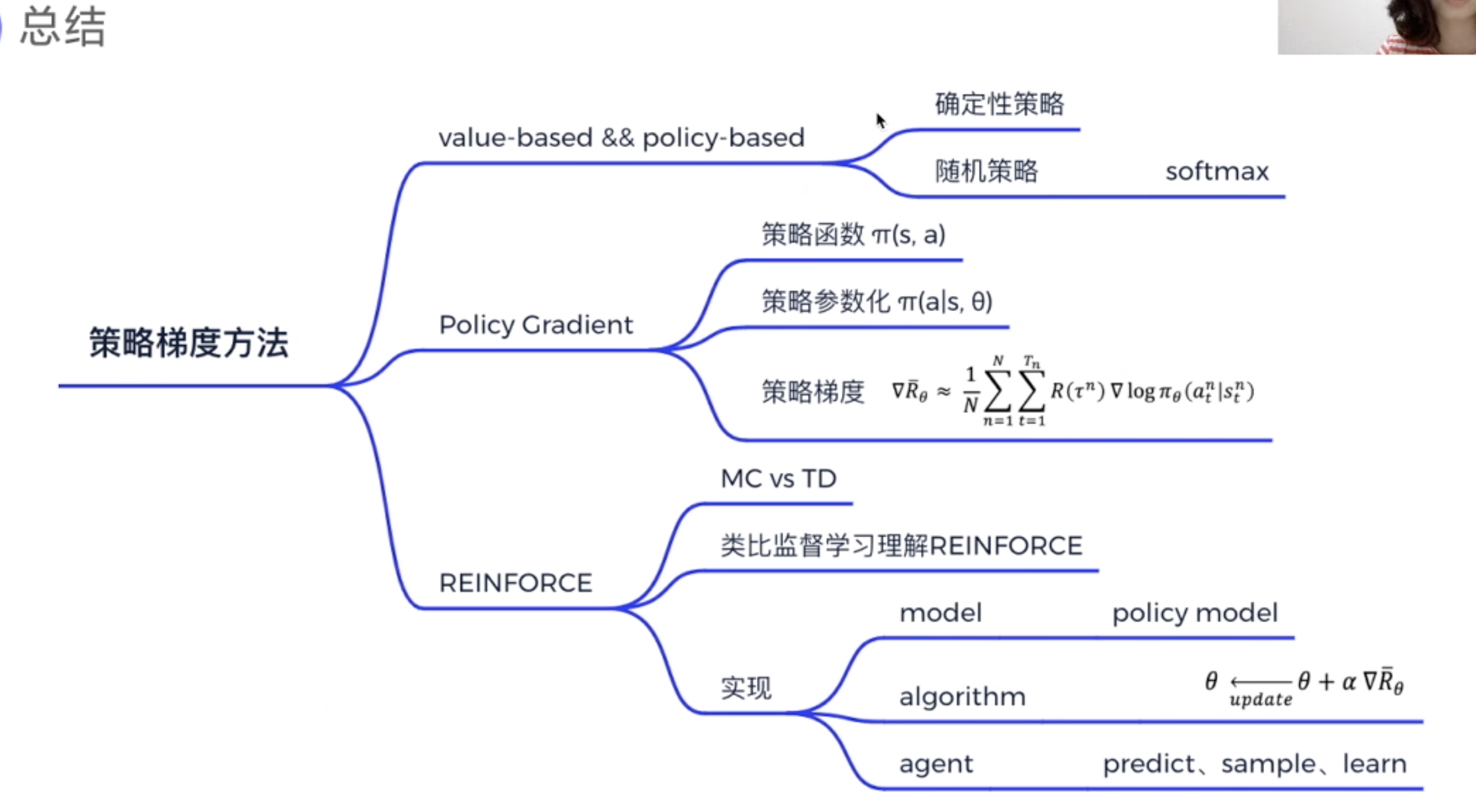
总结