Q 表不适合的场景
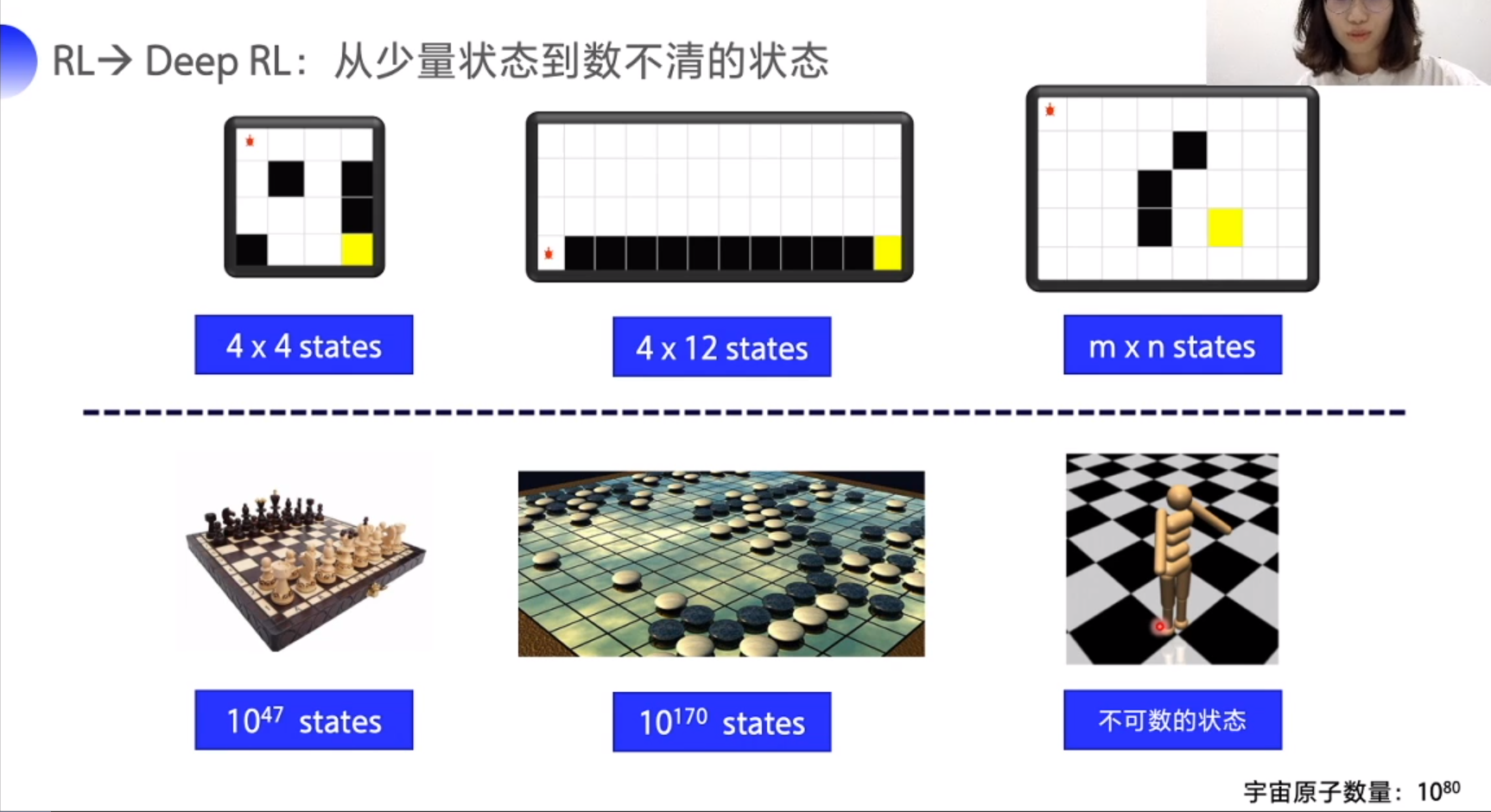
状态太多或者不可数,表格无法容纳
值函数近似
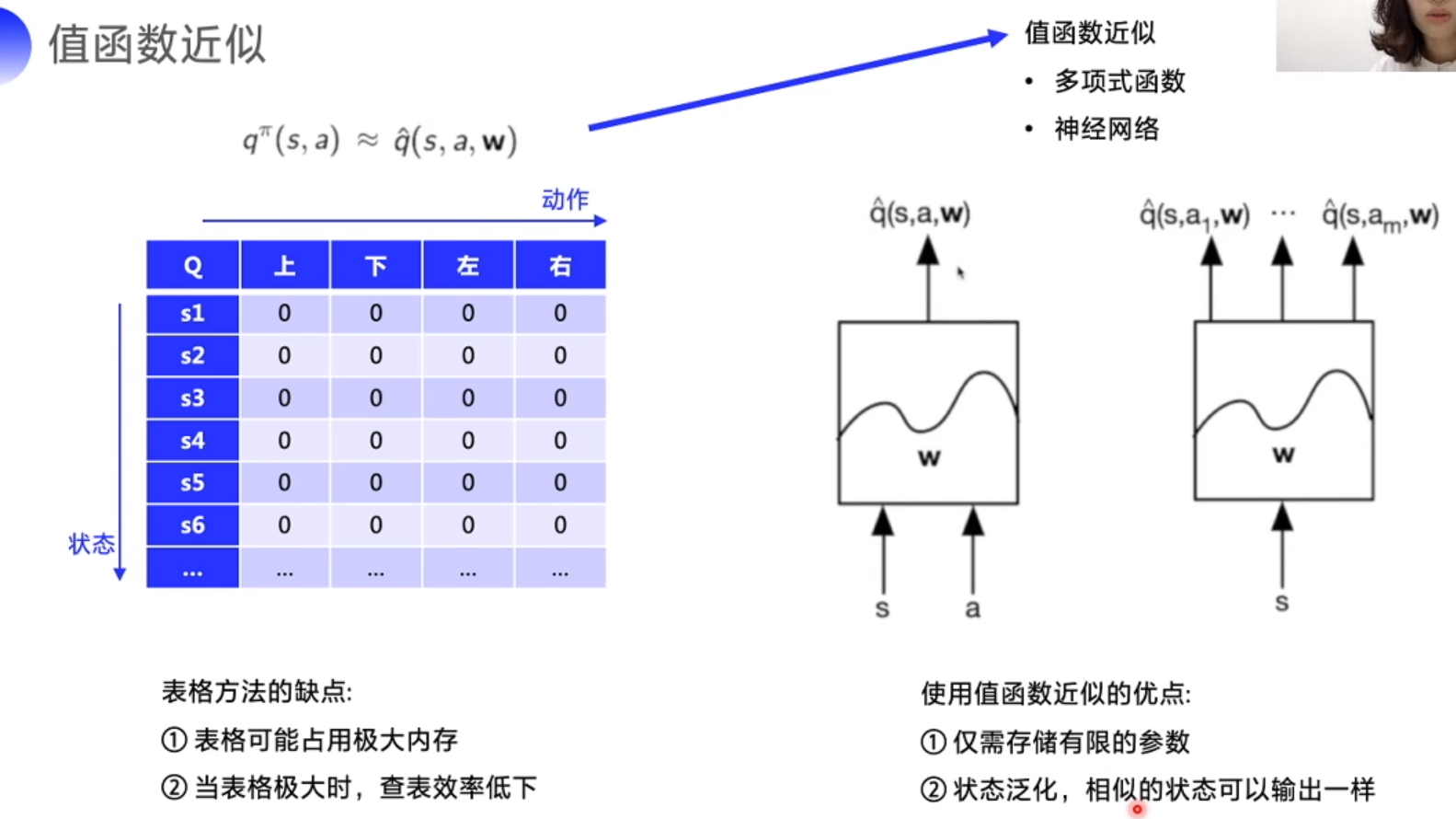
神经网络
拟合任意函数 map x(输入)->y(输出)

DQN
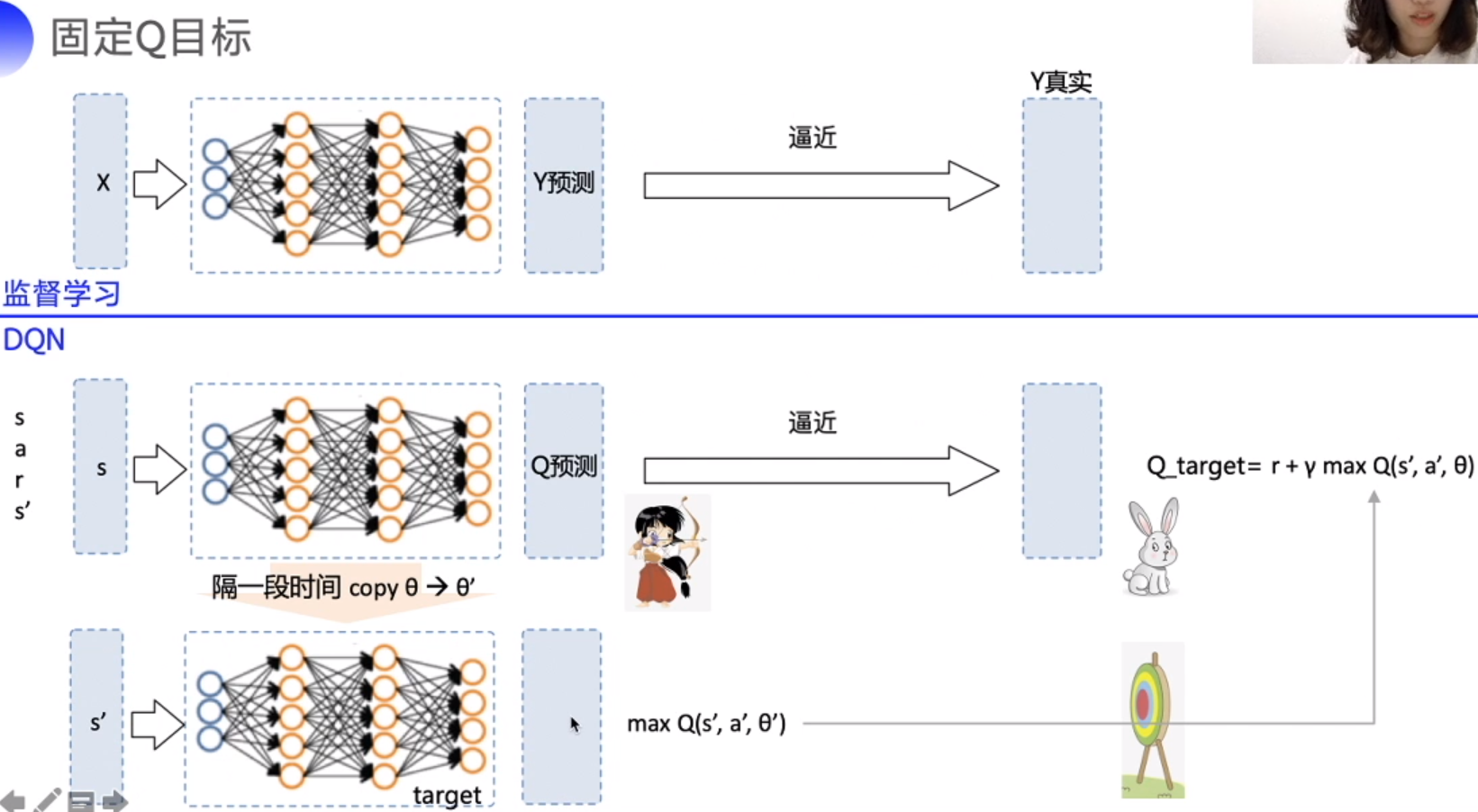
拟合Q表格,找出 s 到 Q 的 maping, 即 Q 表格


s=> Q(), 输出一个包含不同 a 的向量, 逼近 Target Q
创新点
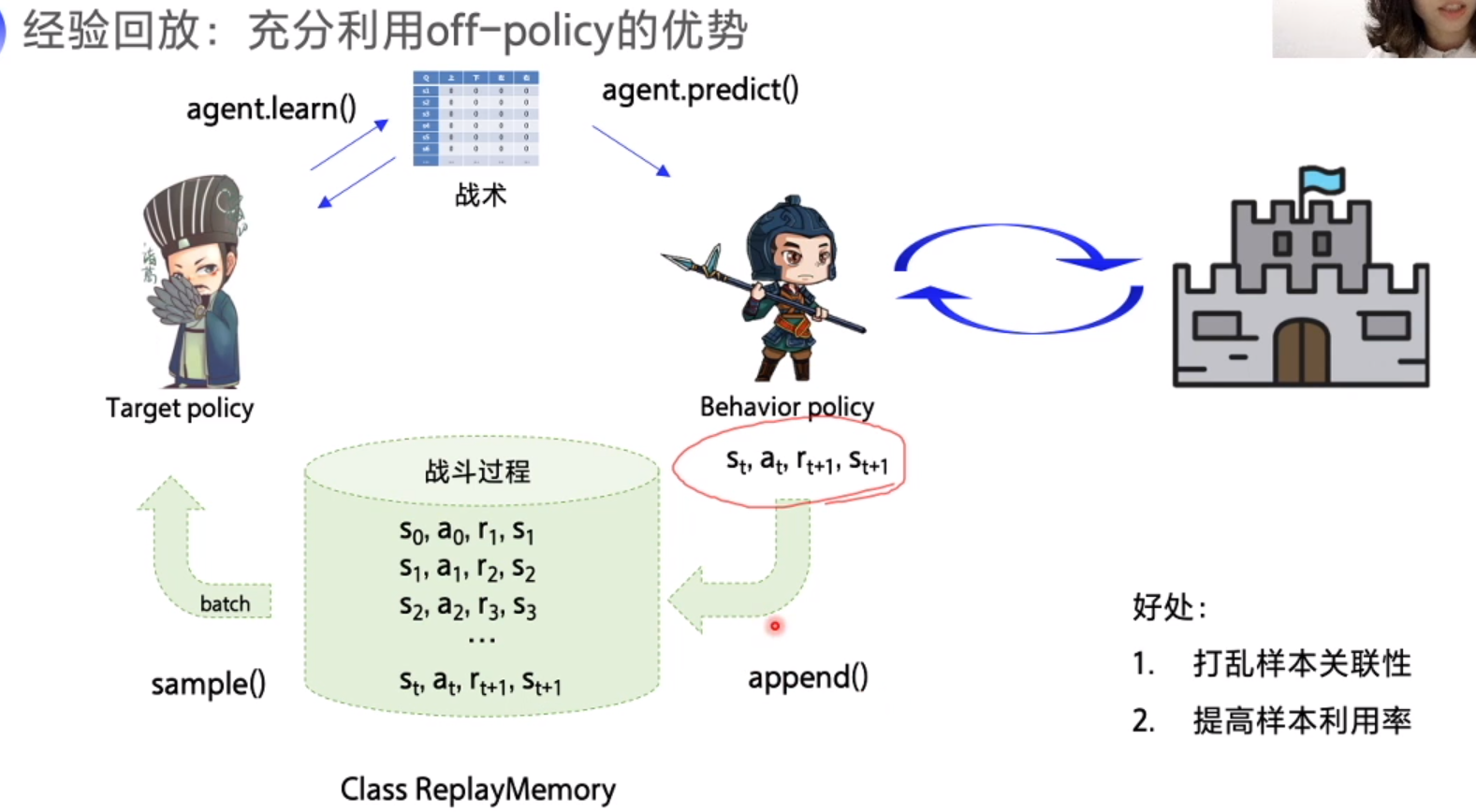
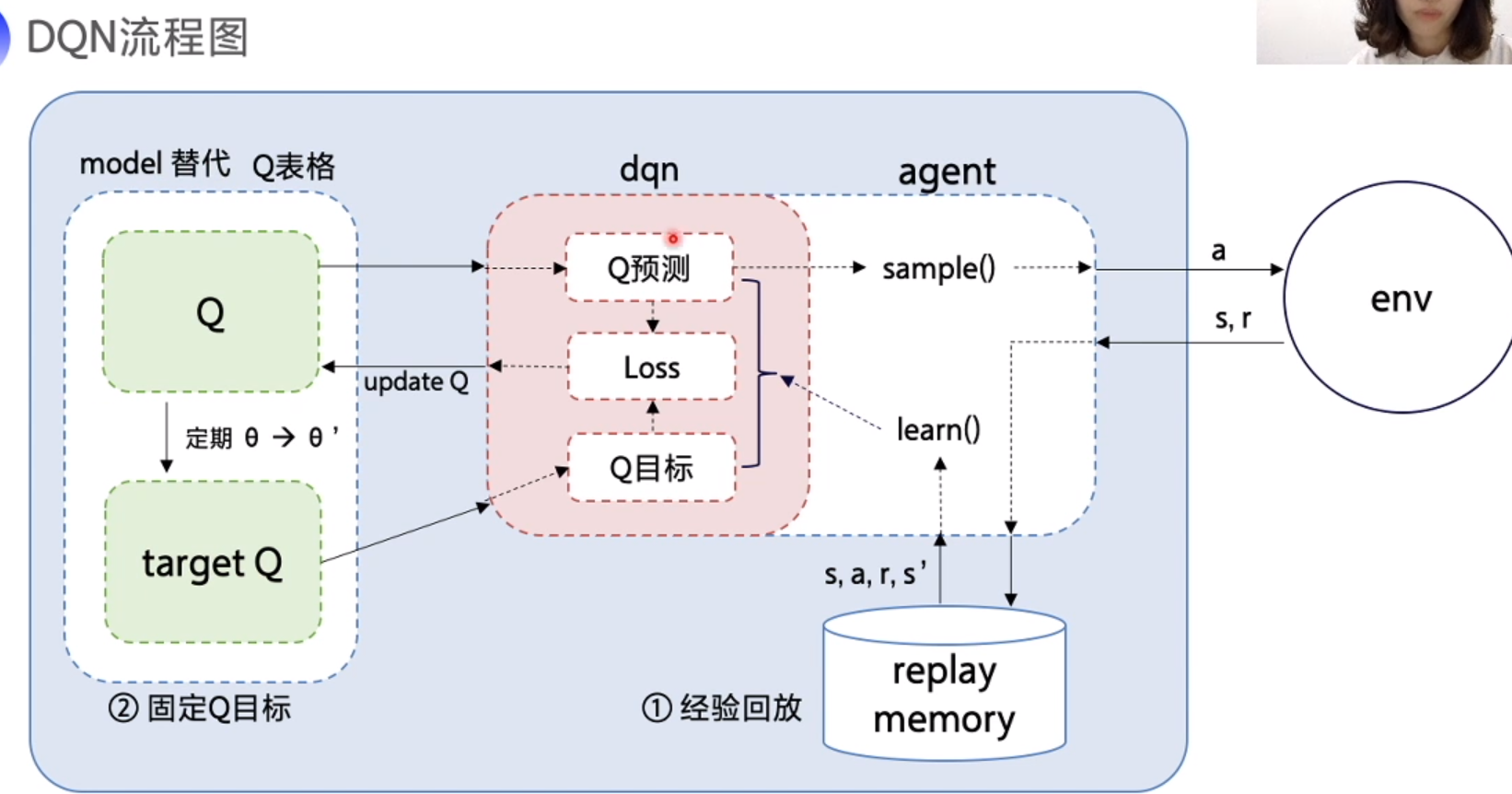
1. 经验回放
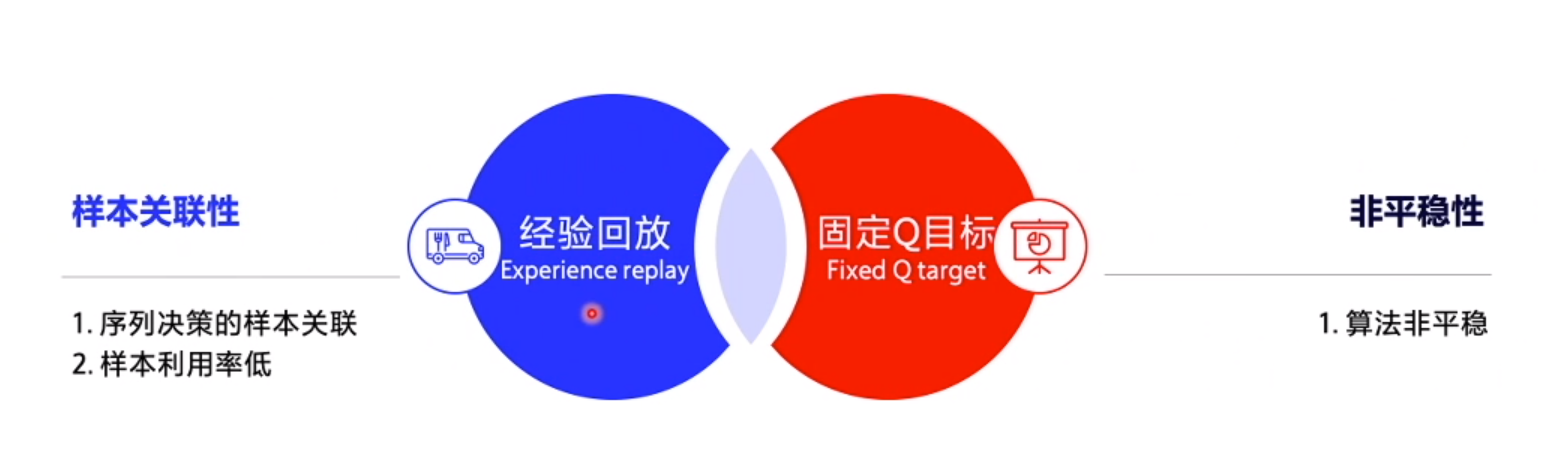
存储一部分经验数据,从中随机选取一部分 (batch) 更新数据
off-policy 回顾
士兵 (behavior policy): 根据战术攻打堡垒,拿到战斗经验,给到军师分析
军师 (Target policy): 根据经验,提升战术,让前方战士打的更好
战术 (Q table)
DQN, 军师从士兵的经验池随机抽取一部分经验。使用缓冲区存储经验,经验可以重复利用。
sample 输入 batch_size 输出抽取的5个数组

2. 固定 Q 目标
保持 Q_target 稳定, 定期 copy Q
DQN 流程图
PARL DQN
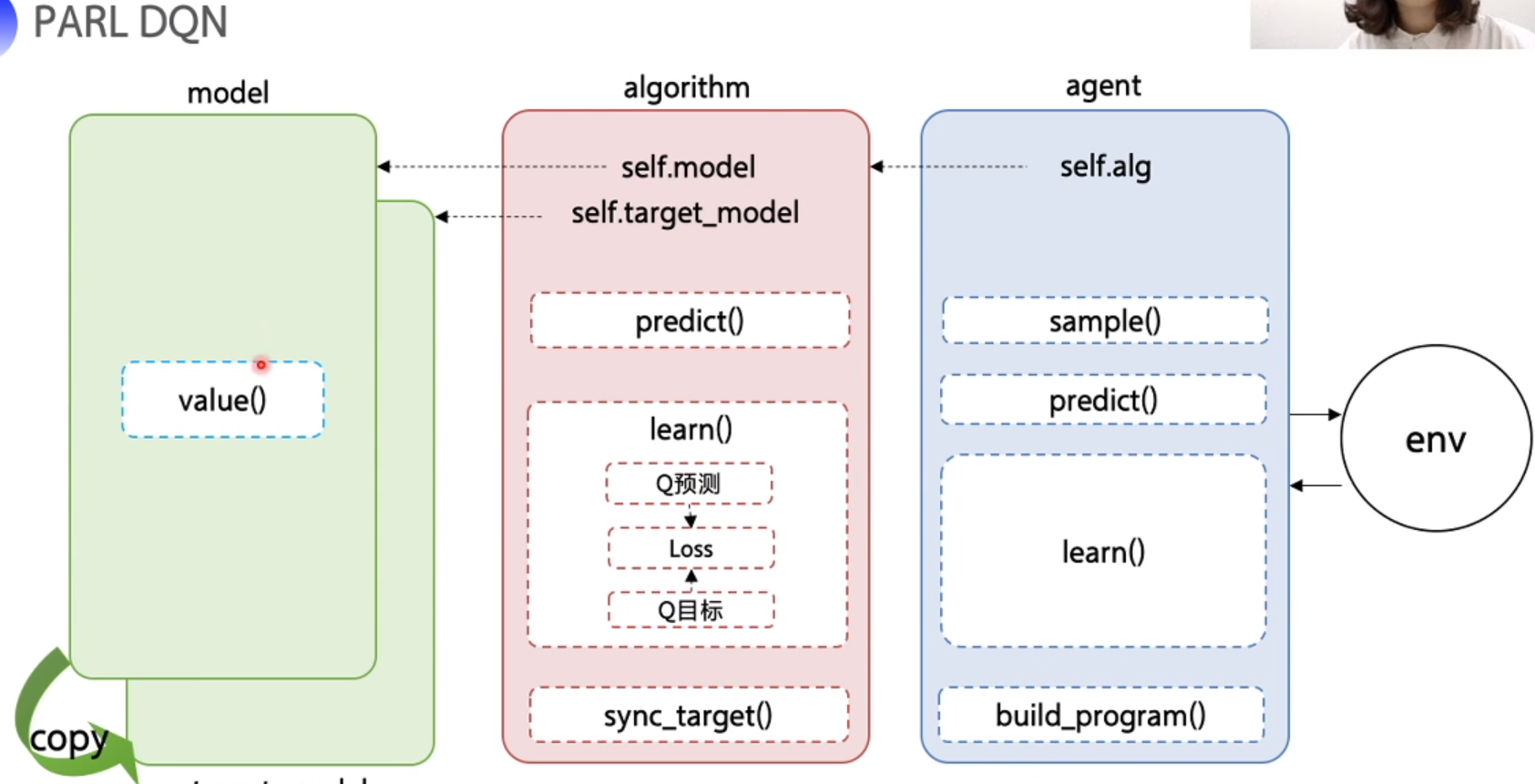
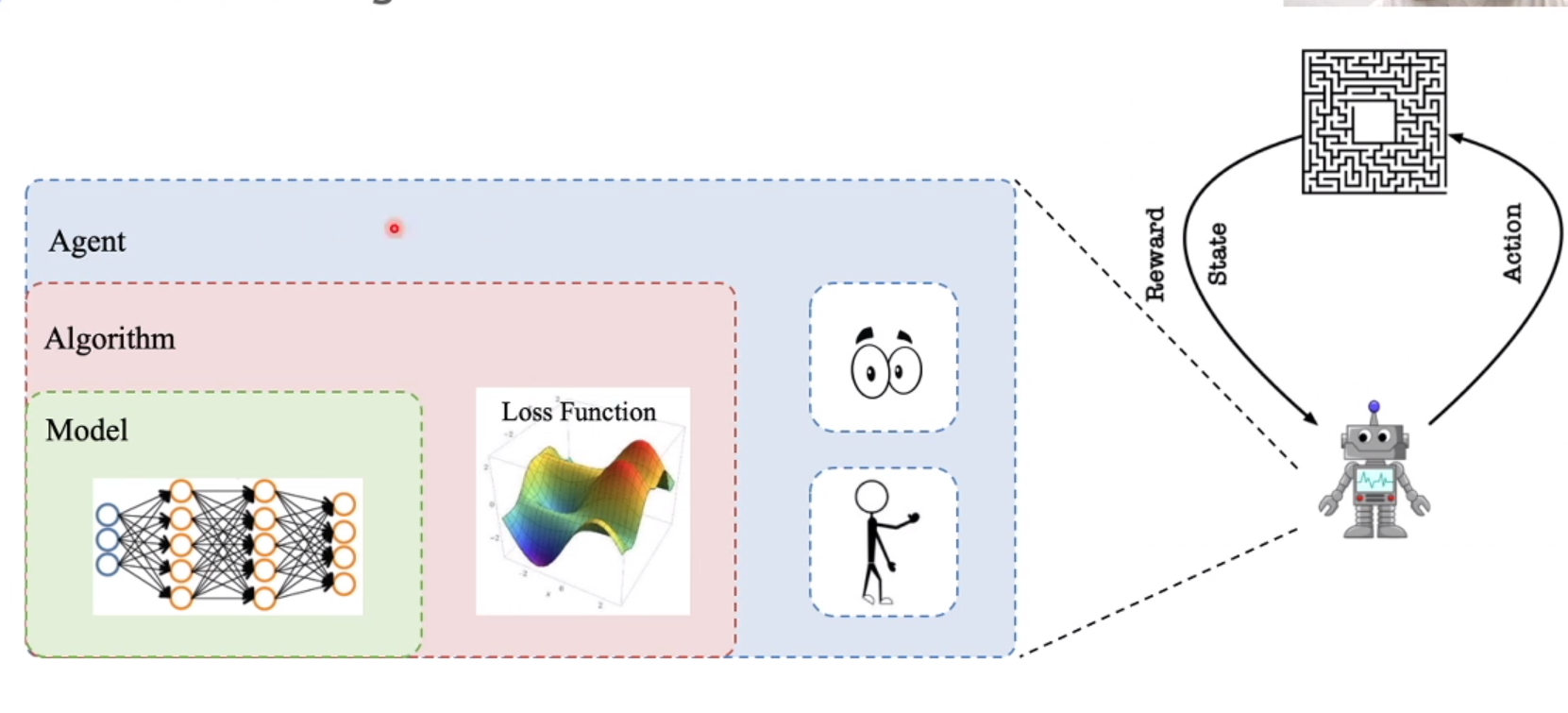
model 神经网络, Algorithm loss function , agent 和环境交互
model.py

输入 obs(S),通过神经网络计算 Q 值
algorithm
init : 输入model 和 参数,copy model, 初始化参数,model , target_model

sync_target: 同步 model, target_model 参数

predict: 返回 model 的值, Q
learn:
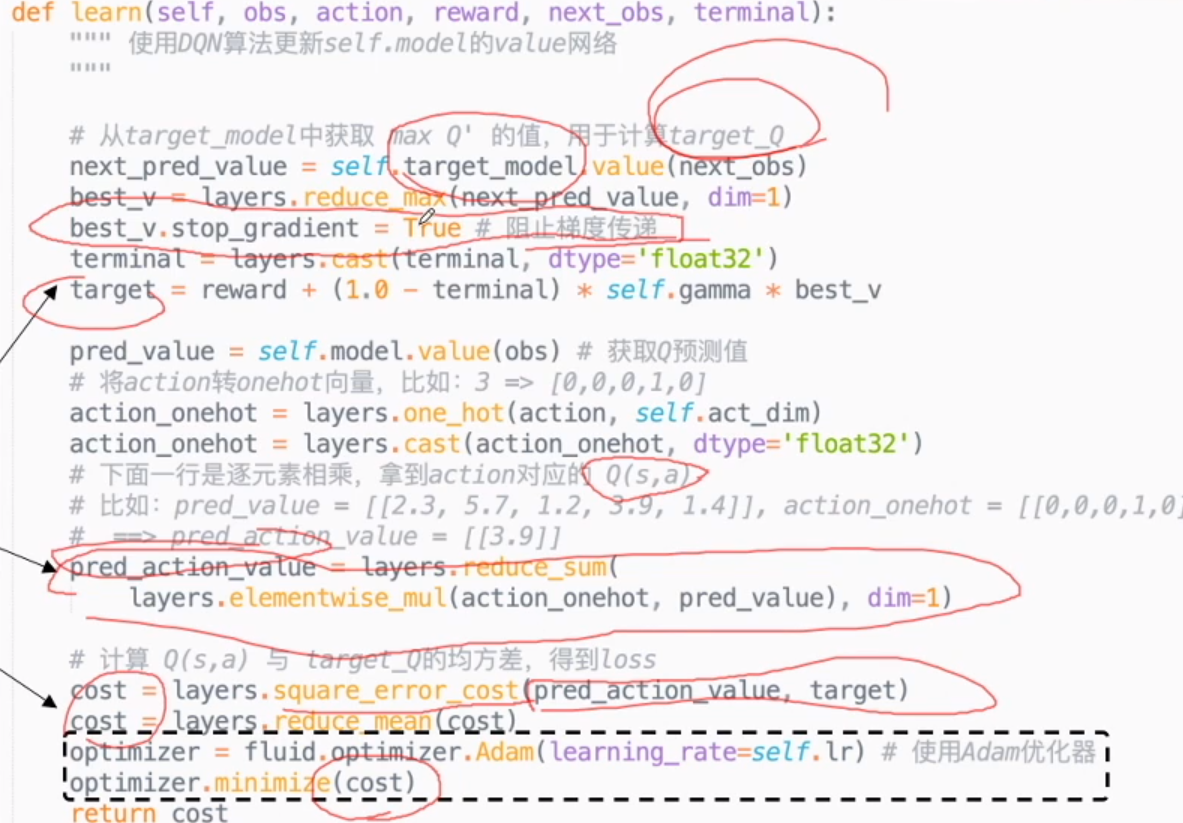
- 计算 target_Q

freeze target_Q, 阻止梯度传递,防止参数更新 - 计算 Q(s,a)
layers.cast(done) true 返回 1, false 返回 0
action 做 onehot, 乘以 Q(s,a) 得到 real Q - 计算 loss
agent:
更新网络,获取 Q 值。
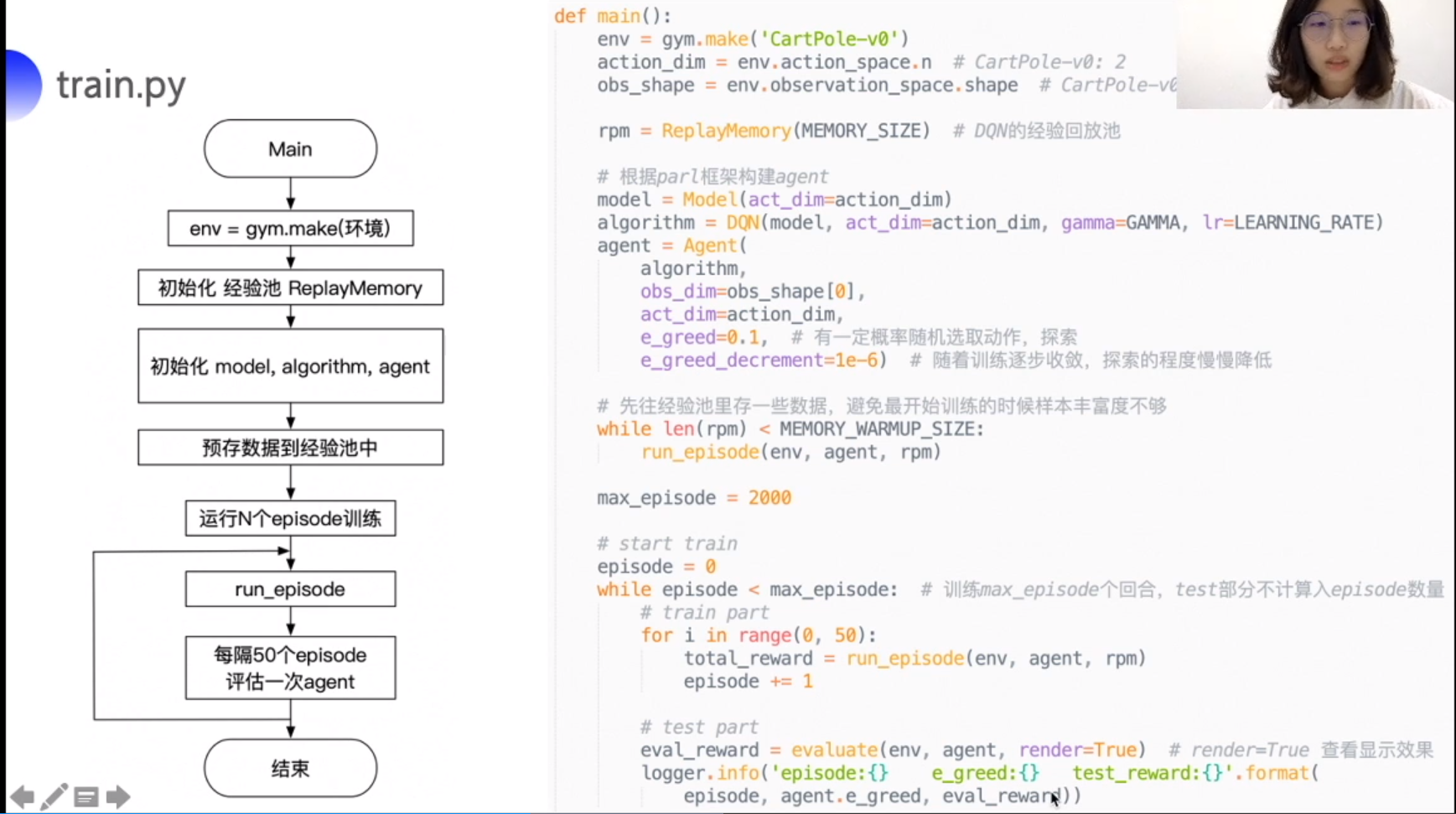
CartPole



总结
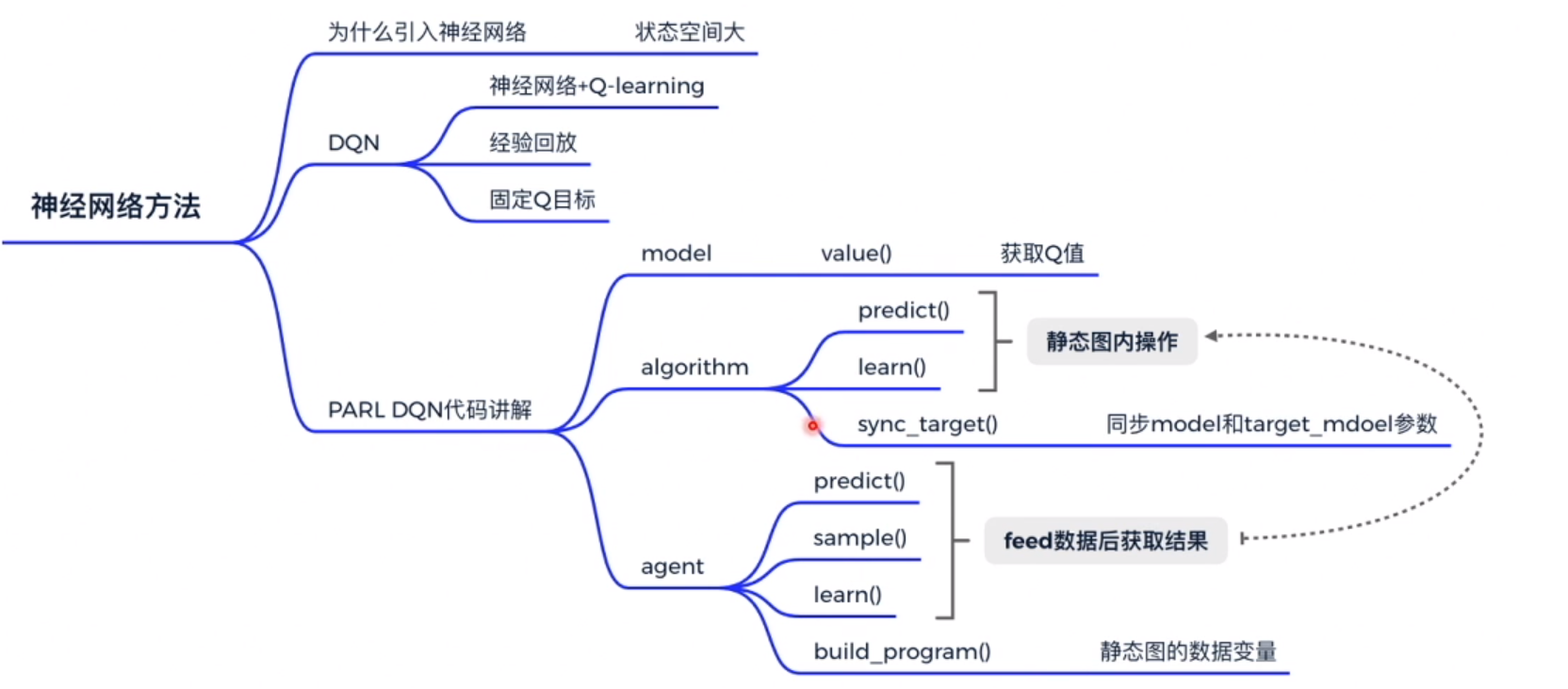
跟 Q learning 主要区别就是使用神经网络计算 Q 值,扩展了 Q 值的范围。并使用经验回放和固定Q目标,重复利用了经验样本和稳定了算法。