强化学习MDP四元组<S, A, P, R>
强化学习是解决跟时间相关的序列决策问题。
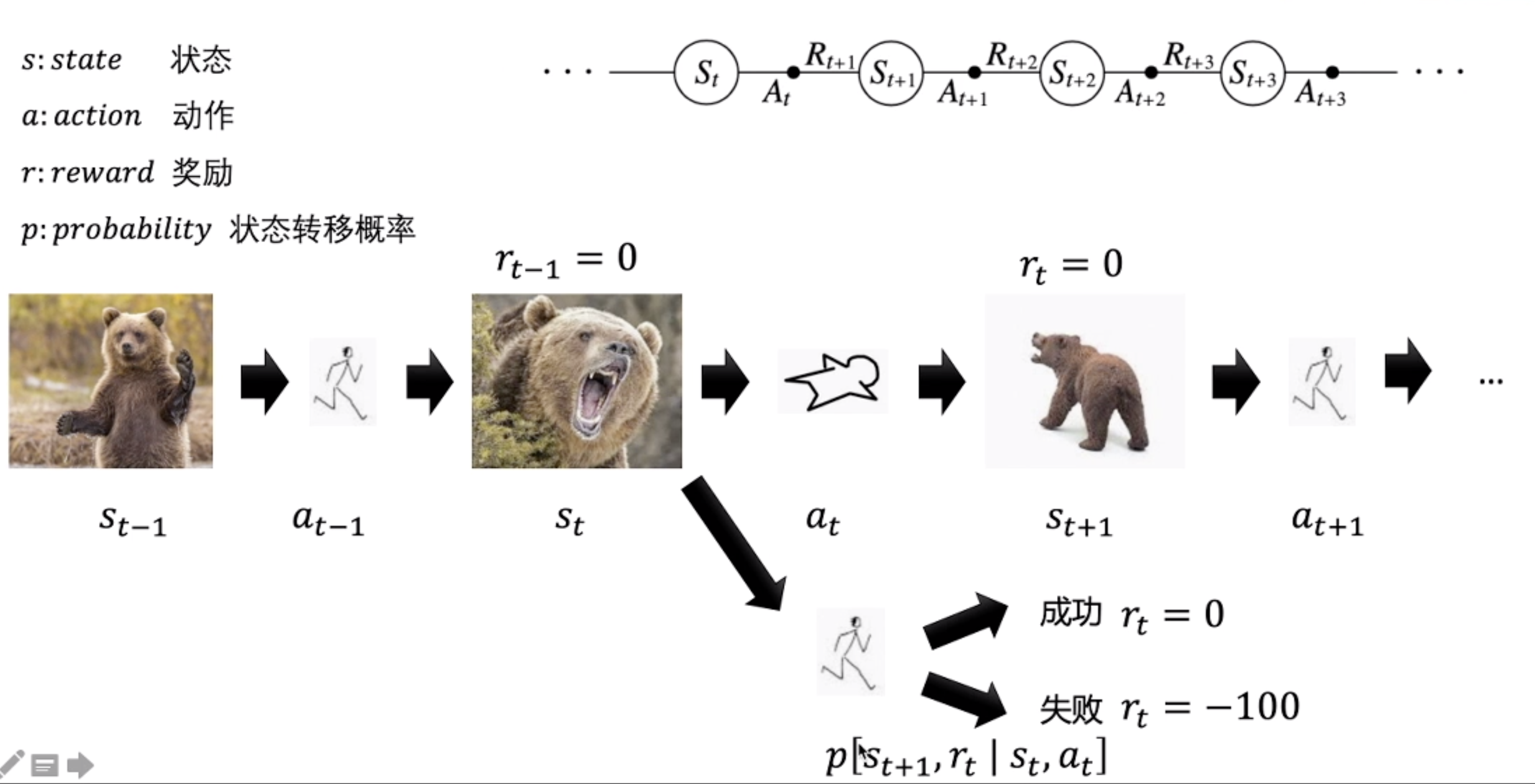
马尔可夫性质: 当前时刻的状态仅与前一时刻的状态和动作有关,与其他时刻的状态和动作条件独立。
马尔可夫决策过程(Markov Decision Process, MDP)是序贯决策(sequential decision)的数学模型,用于在系统状态具有马尔可夫性质的环境中模拟智能体可实现的随机性策略与回报
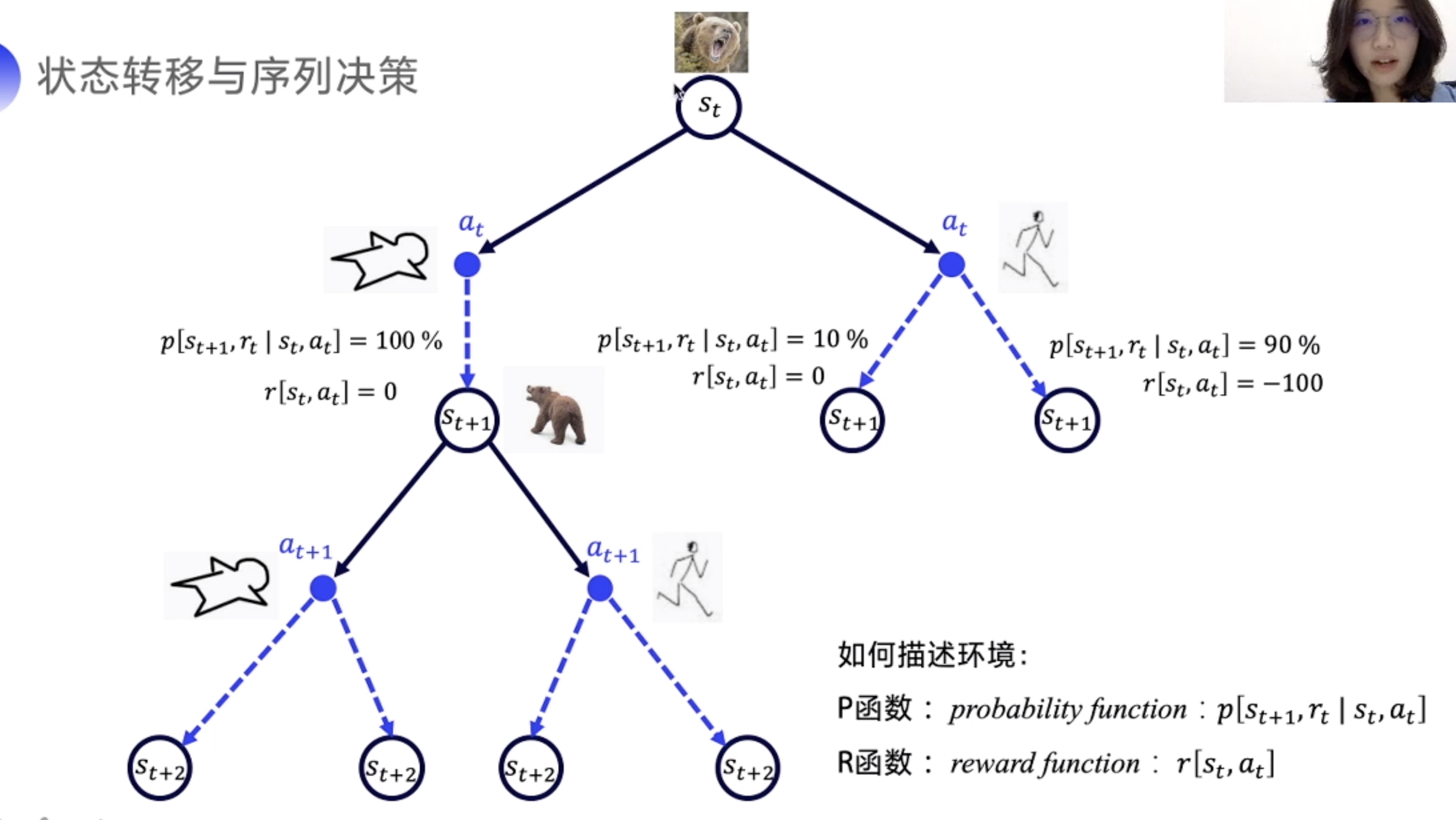
P函数:随机性,转移到另外一种状态的概率
R函数:奖励函数
Model-based vs Model-free
Model based: 如果 P, R 已知,则环境是已知的,可以用动态规划计算最优方案。
Model free: 当解决未知或随机的环境时,即 P, R 未知,可以使用强化学习。
Q 函数
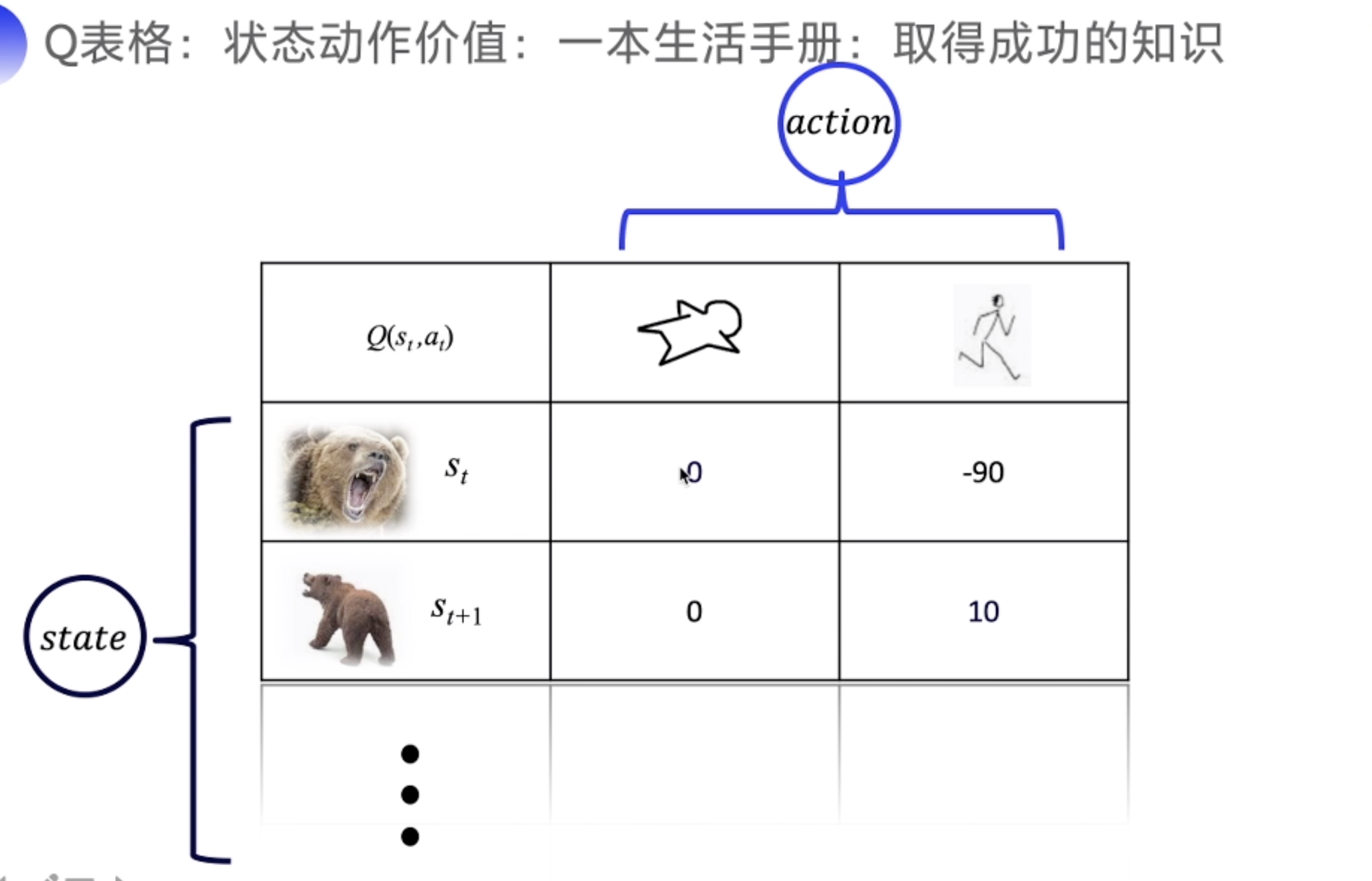
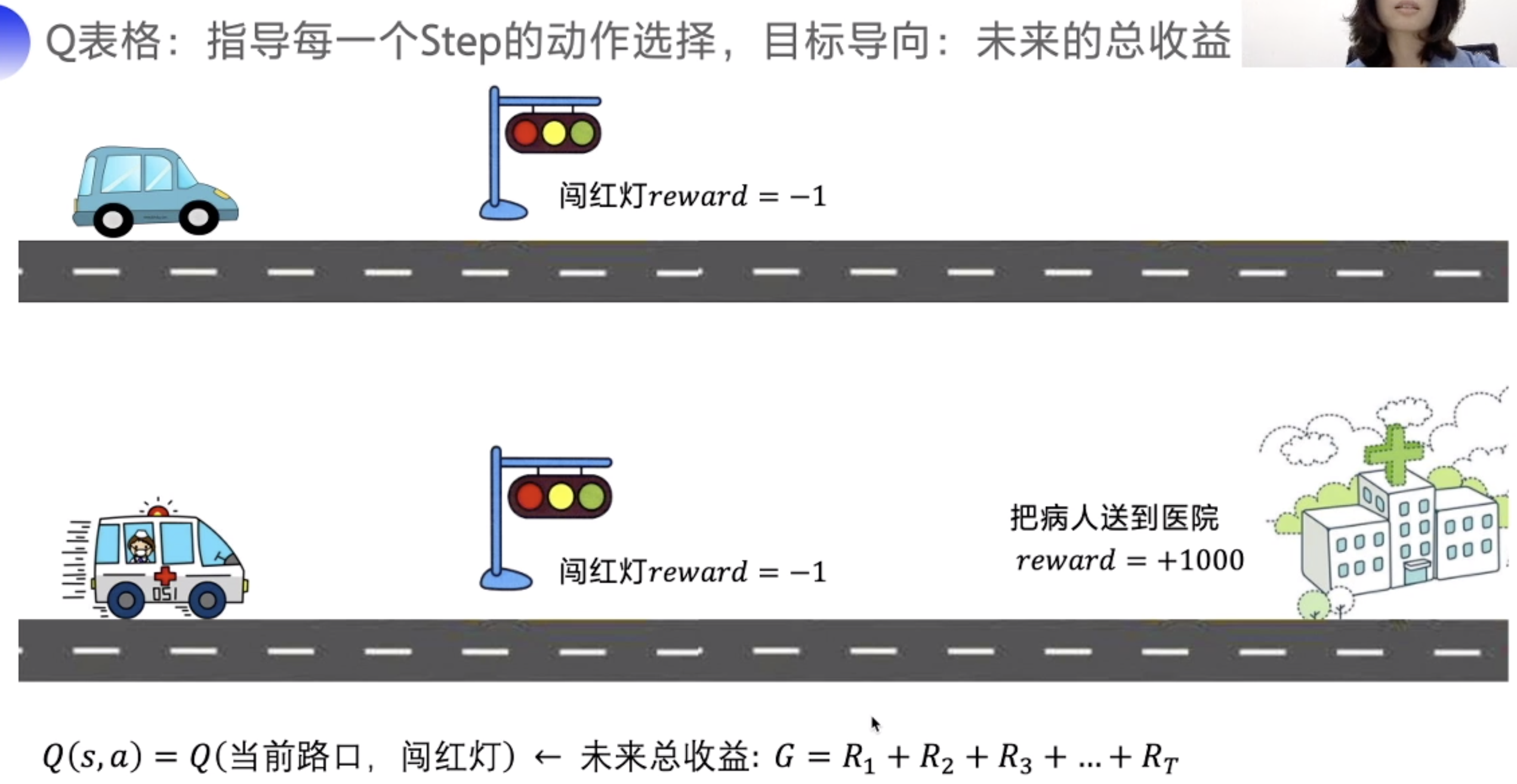
Q的目标是未来的总收益
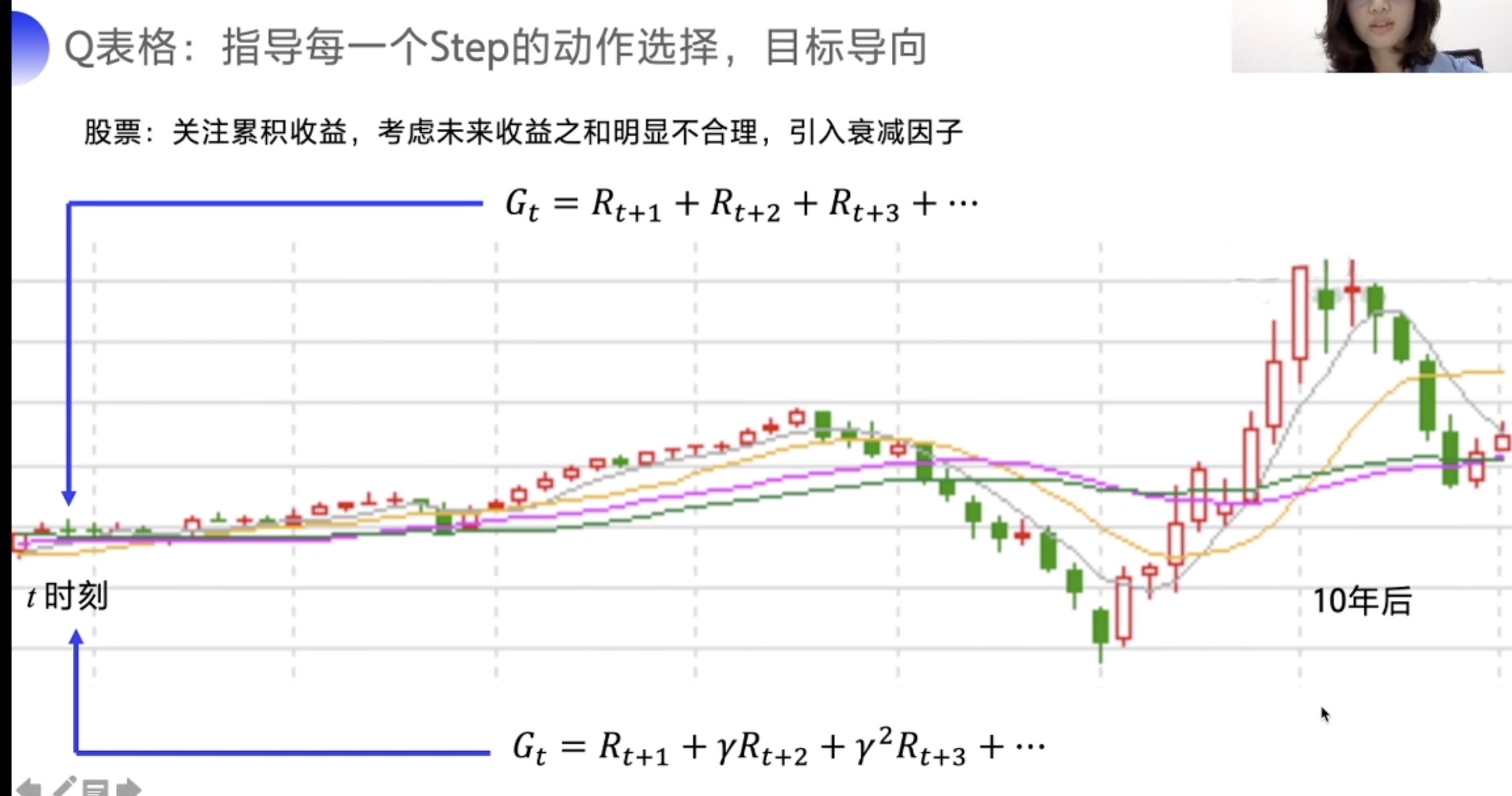
但是当时间过长时,需要加一个 衰减系数,时间越久,对当前的收益影响越小
更新Q表格
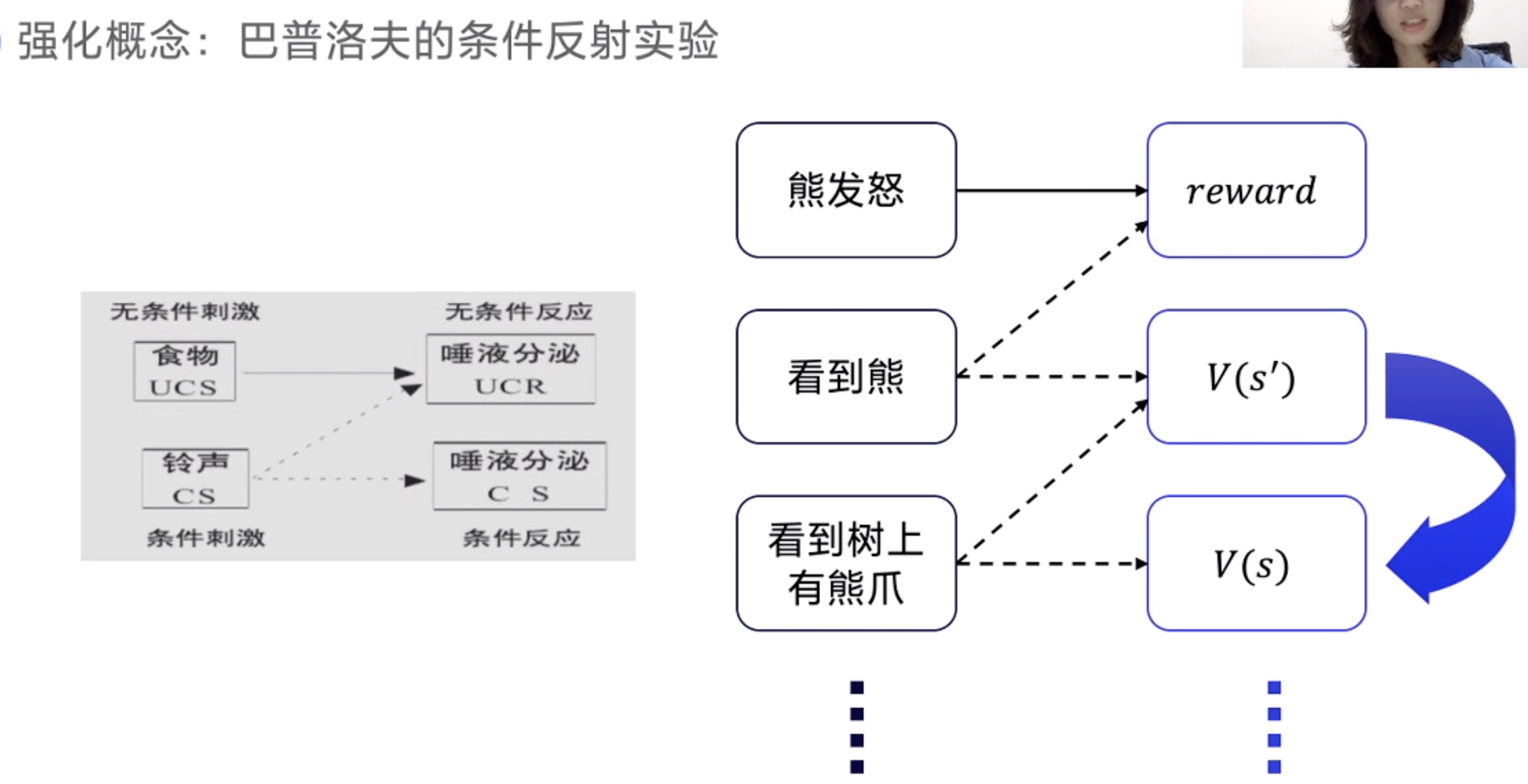
下个状态的价值可以用来强化上一个状态的价值,如结合食物和铃声一起影响狗的食欲(流口水)。

这个公式其实就是把每一步的收益逼近于未来收益之和,即走到这一步获得的总收益。每一次向目标值的方向更新一点。
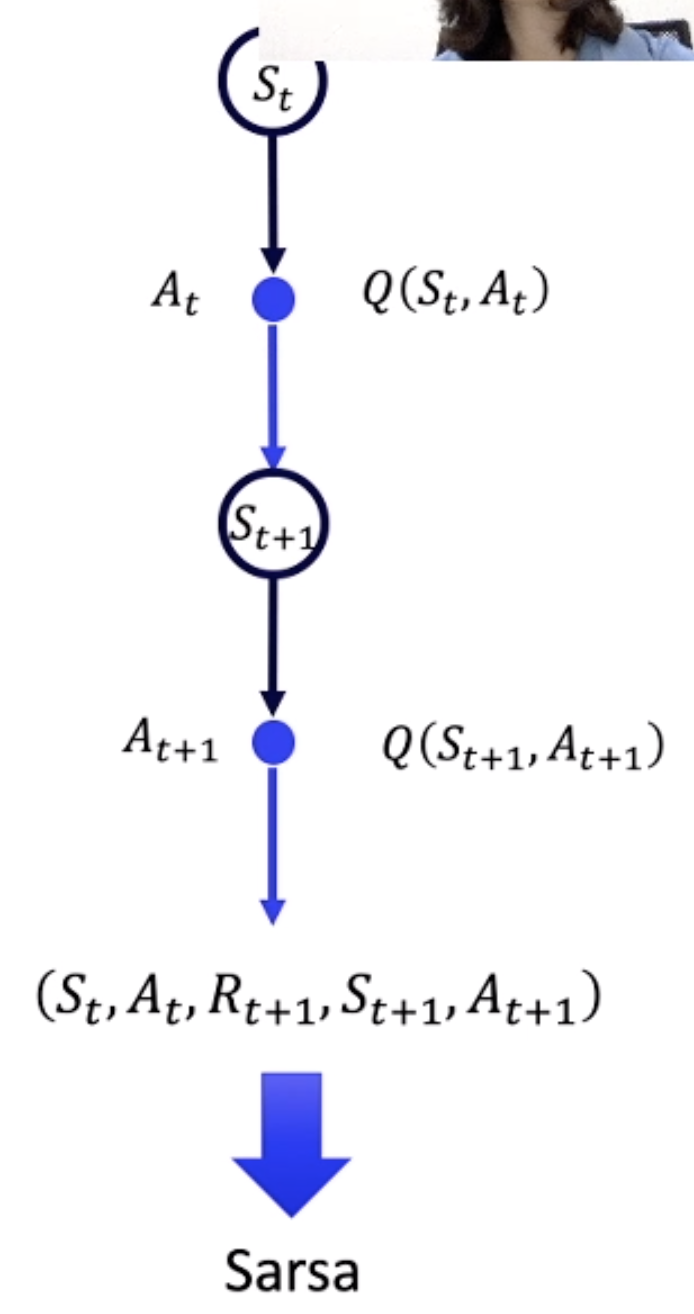
每次跳转到下一个状态时,通过这些Sarsa参数,便可得知当前状态的Q value。

算法:每走一步,先选出要做的动作。再走下一步,通过状态,从Q表拿到, 然后通过下一步和上一步的参数更新
如何通过状态 s 去取出动作 a ? -greedy

Sarsa 代码

Off-Policy
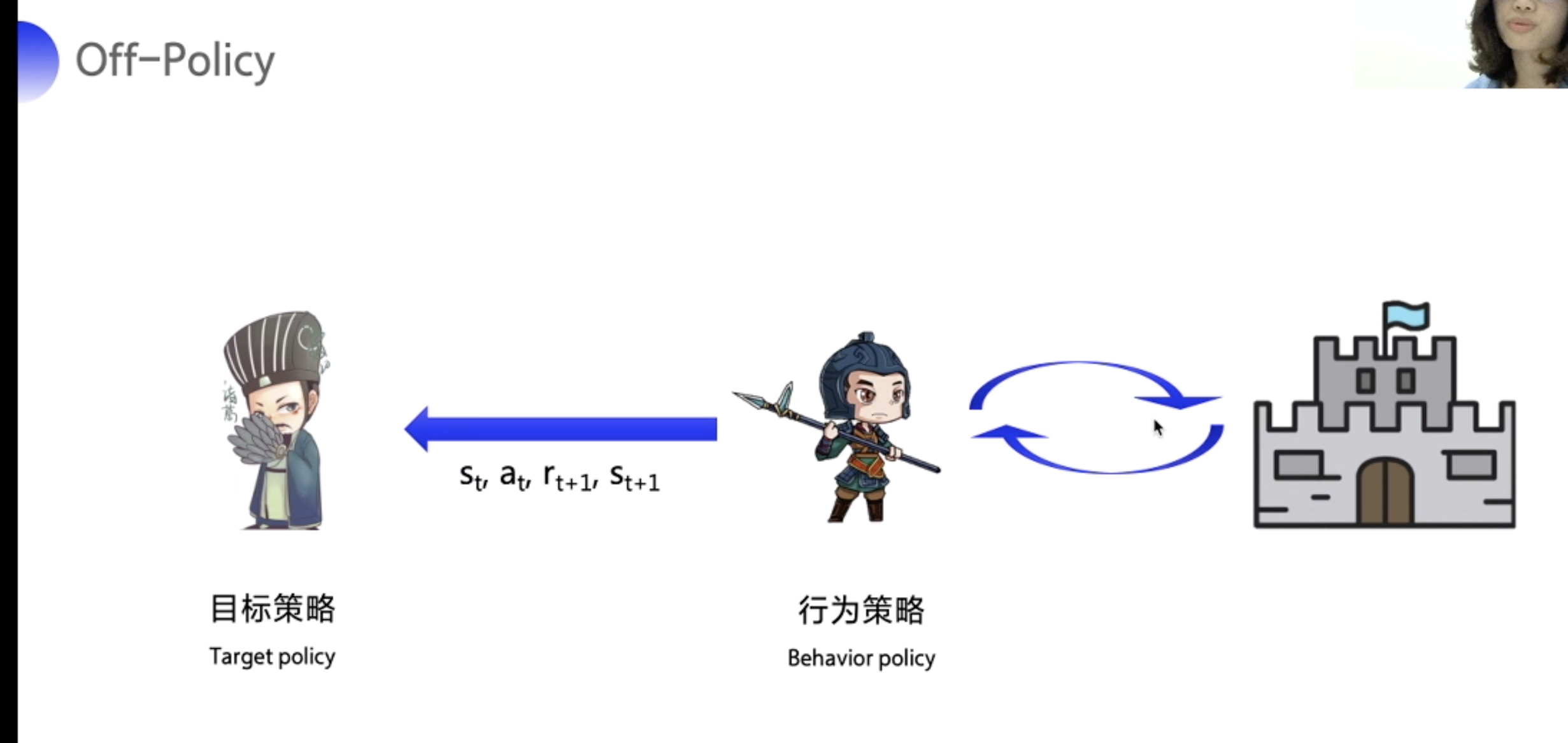
Off-Policy 不和环境交互
Q-learning

Q-learning vs Sarsa
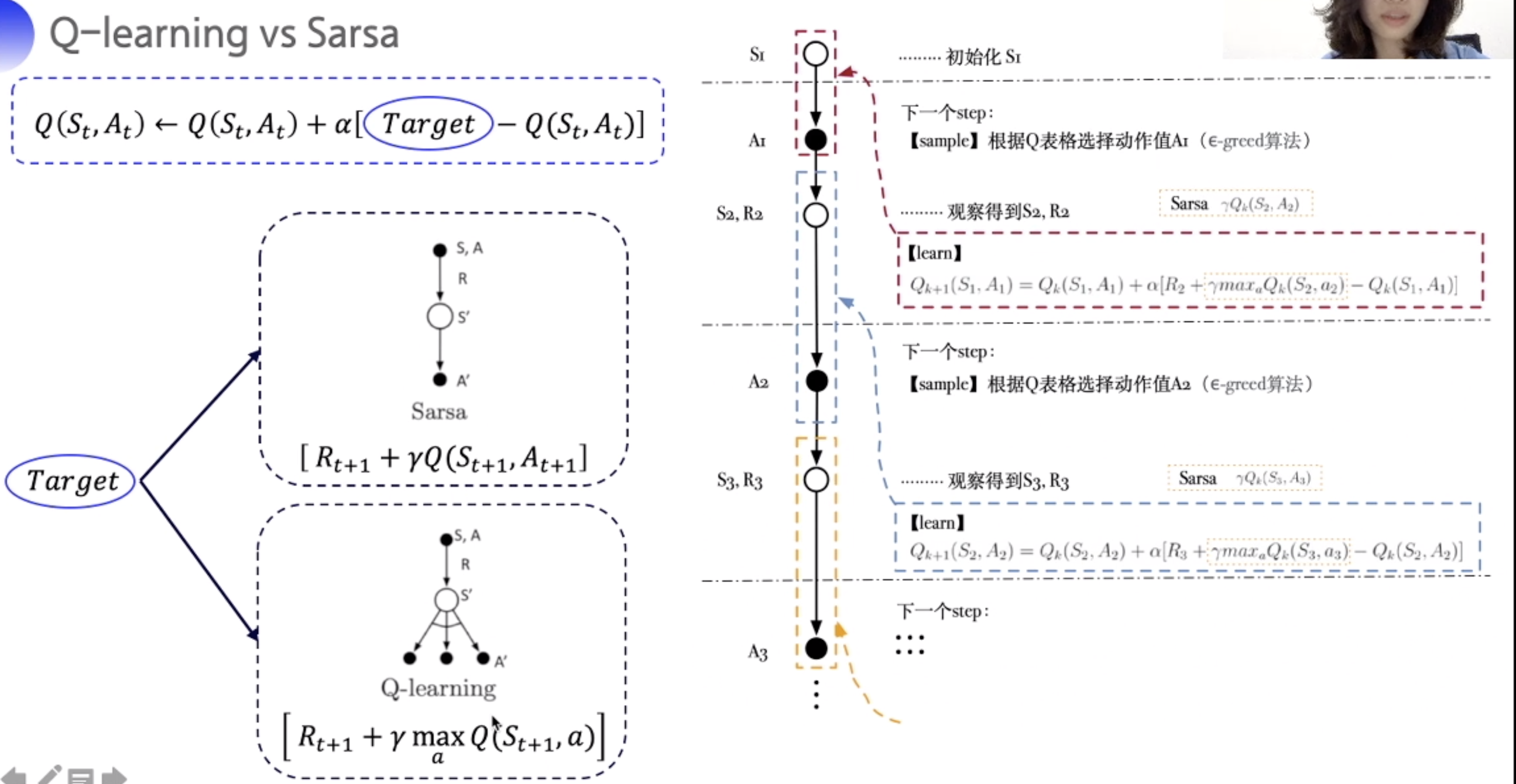
Q-learning 的下个状态选取使Q最大的action

Off-Policy vs On-policy
policy: 策略是指通过状态 s 去取出动作 a 的 方法/概率。Policy specifies an action 𝑎, that is taken in a state 𝑠 (or more precisely, 𝜋 is a probability, that an action 𝑎 is taken in a state 𝑠).
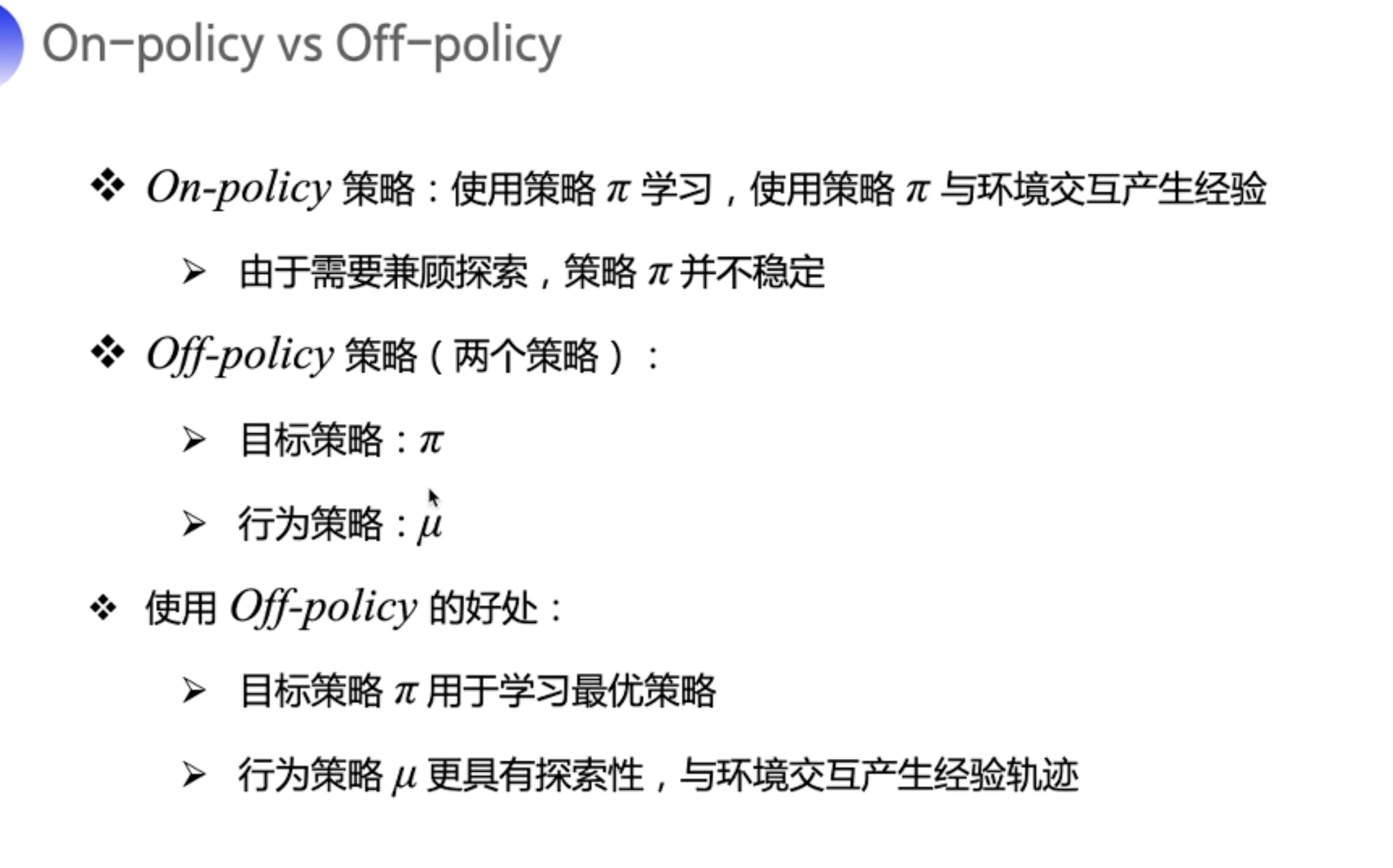
行为策略:用来与环境互动收集情报、产生数据的策略,即训练过程中的策略。 π(a|s)
目标策略:在行为策略产生的数据中不断学习和优化得到的策略,即学习训练完毕后拿去做行为评估的策略。µ(a|s)
区别是
on-policy 通过的与环境交互的经验更新Q, 按以往经验来。 off-policy 就不管之前经验了,通过任意方式获取action, 比如 greedy。
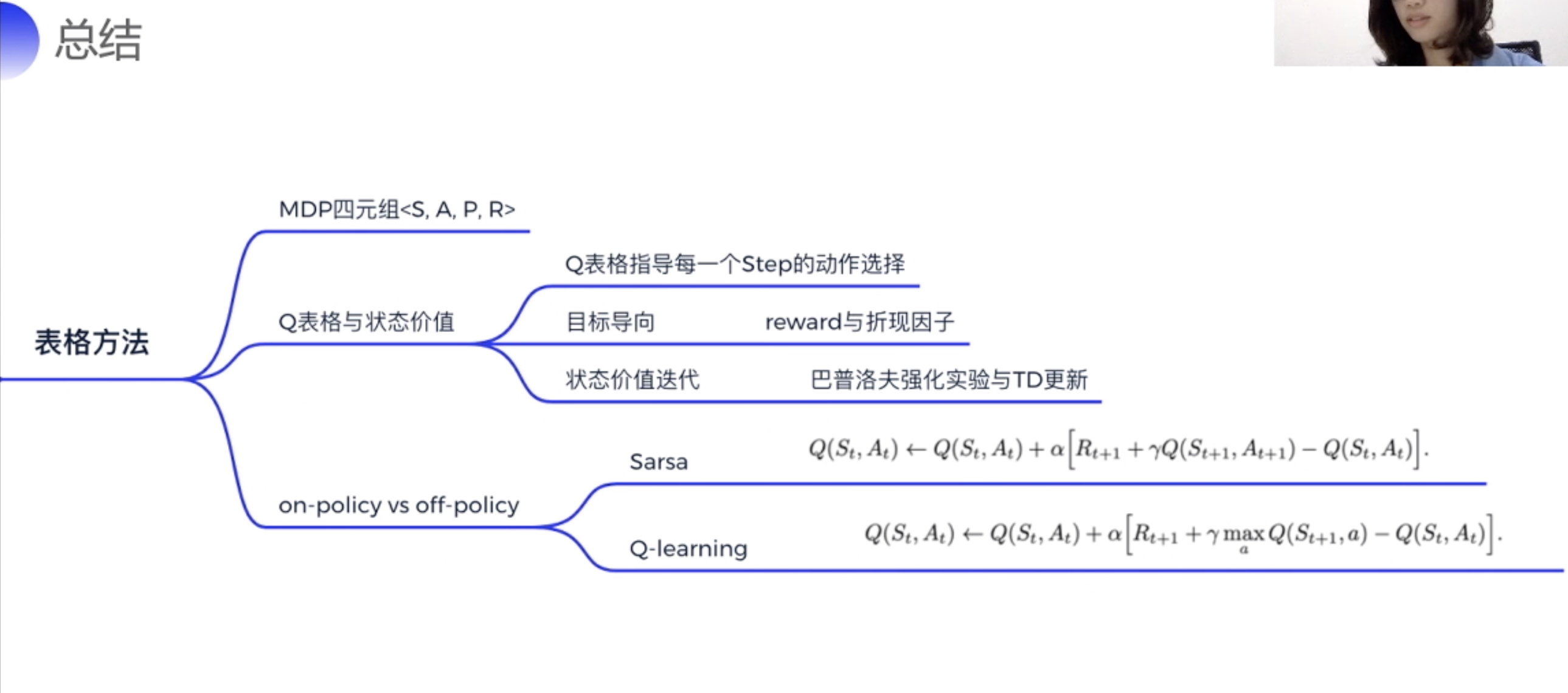
总结
On policy 对于保留目前探索的成果有好处 ,但容易陷入局部最优。不够冒险。
Off policy 够冒险,容易达到全局最优,但收敛更慢,试错更多,不适合现实中试错成本太大的尝试。