第一步把 Q table 看一下
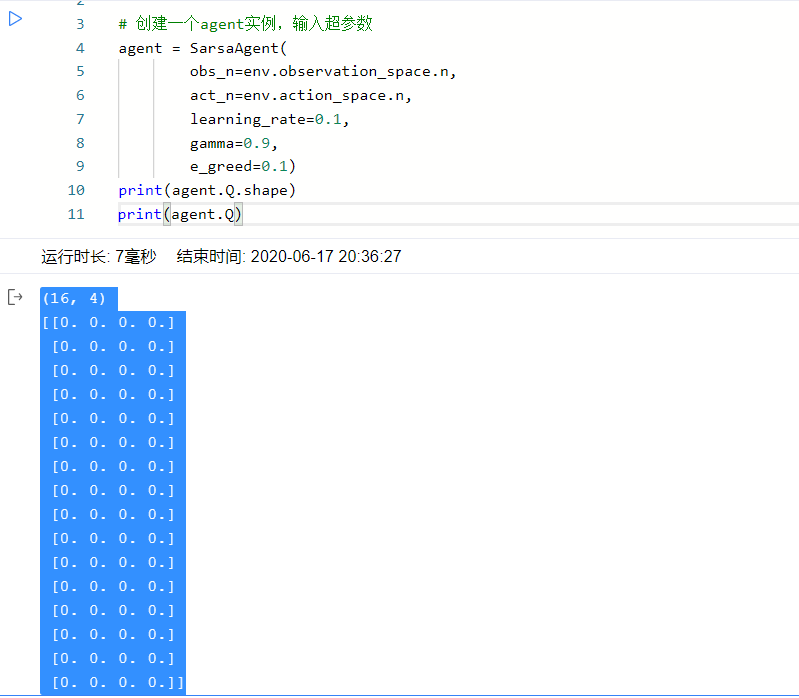
16行4列的np array, 每一格为Q(state, action)的值
sample和predict: 就是-greedy算法

sample
在 0-1 roll 一个数,如果这个数小于等于1- 就触发argmax事件,否则触发随机行动。
可能会用到的函数:
numpy.random.uniform(low=0.0, high=1.0, size=None)
在 low 到 high 范围取size个样本,默认0到1取一个样本
numpy.random.choice(a, size=None, replace=True, p=None)
从 a 列表里随机选size个数, a可以是1维列表或者int, int的话就是 range(a)
Parameters: a: If an ndarray, a random sample is generated from its elements. If an int, the random sample is generated as if a was np.arange(n)
predict
从第 s/obs 行,取 Q 值最大的 a。=> find the max index of value,即求最大值的坐标。
因为有可能有多个最大值,我们不想每次都走同一个action, 所以从这些最大值的坐标随机出一个。
可能会用到的函数:
从 2D Numpy Array 选某行: ndArray[row_index] 或者 ndArray[row_index, :]
numpy.where(condition) 输出满足条件 ((condition)) 元素的坐标 (等价于numpy.nonzero)。这里的坐标以tuple的形式给出。
这里 np.where 返回类似 (array([0, 1, 2, 3]),) 元组这种格式。所以用下标取出第一个array
learn

这里就是先把方括号里的算出来,再乘 加上原来的值
Q learning 的 sample 和 predict 和 Sarsa 完全一样,唯一就是 更新 Q 的公式不同。

显示视图
把 test_episode 里的这两行反注释掉
gridworld.py 下载地址:https://raw.githubusercontent.com/PaddlePaddle/PARL/develop/examples/tutorials/lesson1/gridworld.py
from gridworld import FrozenLakeWapper
env = gym.make("FrozenLake-v0", is_slippery=False)
env = FrozenLakeWapper(env)
错误:no display name and no $DISPLAY environment variable
Jupyter没有窗口环境,要本地运行,或者远程terminal跑才行
结果展示
Sarsa
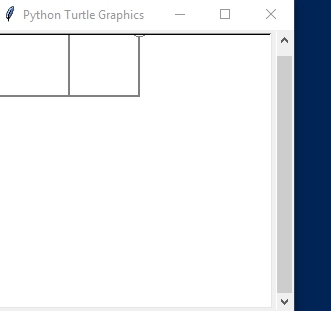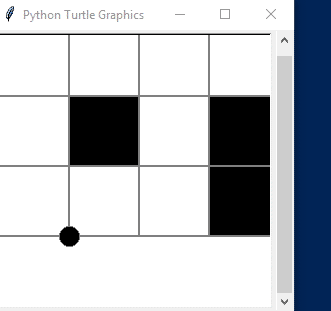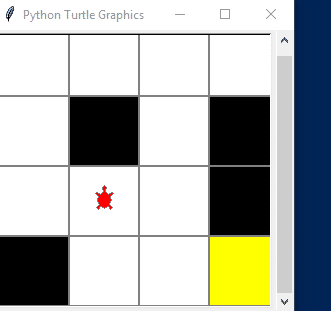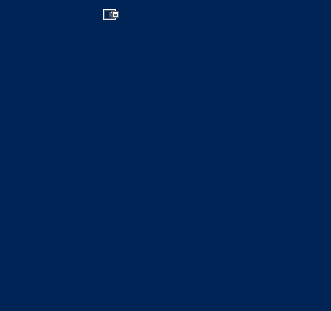
Q-learning